The ambition to speed up scientific discovery by means of AI has been longstanding, with early efforts such because the Oak Ridge Utilized AI Mission courting again to 1979. Newer developments in basis fashions have demonstrated the feasibility of totally automated analysis pipelines, enabling AI methods to autonomously conduct literature opinions, formulate hypotheses, design experiments, analyze outcomes, and even generate scientific papers. Moreover, they’ll streamline scientific workflows by automating repetitive duties, permitting researchers to concentrate on higher-level conceptual work. Nevertheless, regardless of these promising developments, the analysis of AI-driven analysis stays difficult as a result of lack of standardized benchmarks that may comprehensively assess their capabilities throughout completely different scientific domains.
Current research have addressed this hole by introducing benchmarks that consider AI brokers on varied software program engineering and machine studying duties. Whereas frameworks exist to check AI brokers on well-defined issues like code era and mannequin optimization, most present benchmarks don’t totally assist open-ended analysis challenges, the place a number of options may emerge. Moreover, these frameworks usually lack flexibility in assessing various analysis outputs, equivalent to novel algorithms, mannequin architectures, or predictions. To advance AI-driven analysis, there’s a want for analysis methods that incorporate broader scientific duties, facilitate experimentation with completely different studying algorithms, and accommodate varied types of analysis contributions. By establishing such complete frameworks, the sphere can transfer nearer to realizing AI methods able to independently driving significant scientific progress.
Researchers from the College Faculty London, College of Wisconsin–Madison, College of Oxford, Meta, and different institutes have launched a brand new framework and benchmark for evaluating and growing LLM brokers in AI analysis. This method, the primary Fitness center surroundings for ML duties, facilitates the examine of RL methods for coaching AI brokers. The benchmark, MLGym-Bench, contains 13 open-ended duties spanning laptop imaginative and prescient, NLP, RL, and recreation principle, requiring real-world analysis abilities. A six-level framework categorizes AI analysis agent capabilities, with MLGym-Bench specializing in Degree 1: Baseline Enchancment, the place LLMs optimize fashions however lack scientific contributions.
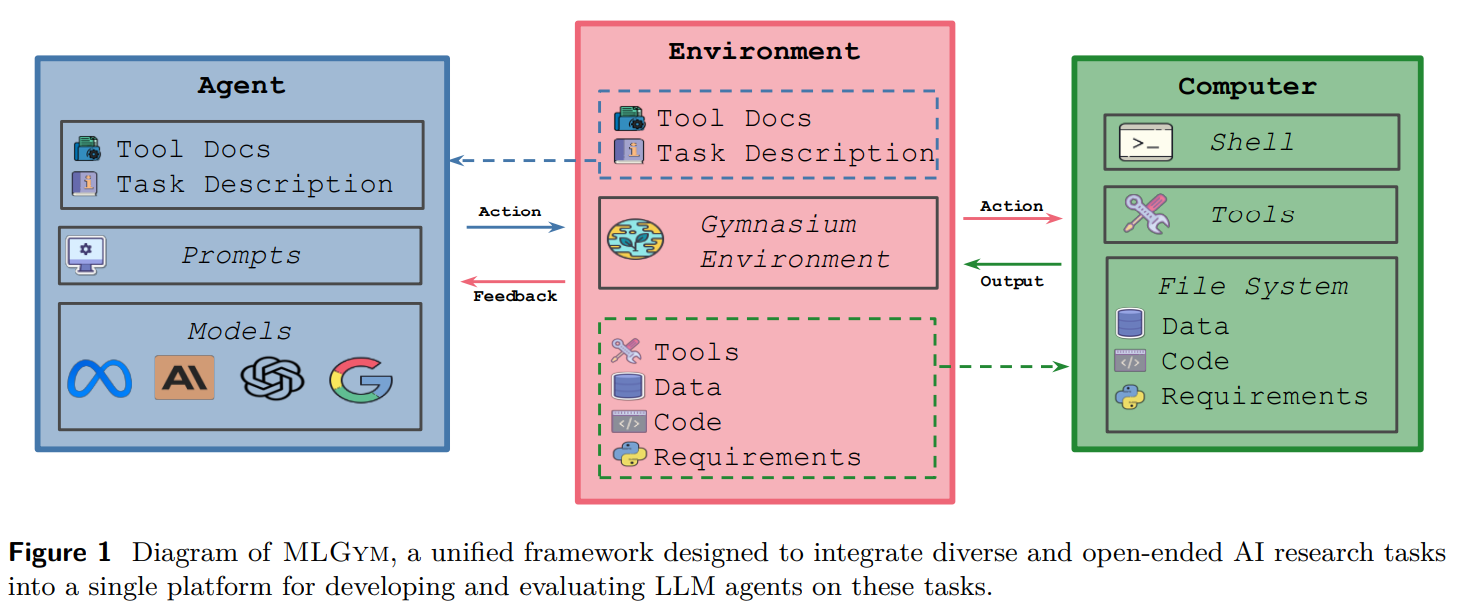
MLGym is a framework designed to judge and develop LLM brokers for ML analysis duties by enabling interplay with a shell surroundings by means of sequential instructions. It includes 4 key parts: Brokers, Surroundings, Datasets, and Duties. Brokers execute bash instructions, handle historical past, and combine exterior fashions. The surroundings offers a safe Docker-based workspace with managed entry. Datasets are outlined individually from duties, permitting reuse throughout experiments. Duties embody analysis scripts and configurations for various ML challenges. Moreover, MLGym affords instruments for literature search, reminiscence storage, and iterative validation, making certain environment friendly experimentation and flexibility in long-term AI analysis workflows.
The examine employs a SWE-Agent mannequin designed for the MLGYM surroundings, following a ReAct-style decision-making loop. 5 state-of-the-art fashions—OpenAI O1-preview, Gemini 1.5 Professional, Claude-3.5-Sonnet, Llama-3-405b-Instruct, and GPT-4o—are evaluated underneath standardized settings. Efficiency is assessed utilizing AUP scores and efficiency profiles, evaluating fashions based mostly on Greatest Try and Greatest Submission metrics. OpenAI O1-preview achieves the very best general efficiency, with Gemini 1.5 Professional and Claude-3.5-Sonnet intently following. The examine highlights efficiency profiles as an efficient analysis technique, demonstrating that OpenAI O1-preview constantly ranks among the many high fashions throughout varied duties.
In conclusion, the examine highlights the potential and challenges of utilizing LLMs as scientific workflow brokers. MLGym and MLGymBench reveal adaptability throughout varied quantitative duties however reveal enchancment gaps. Increasing past ML, testing interdisciplinary generalization, and assessing scientific novelty are key areas for progress. The examine emphasizes the significance of information openness to reinforce collaboration and discovery. As AI analysis progresses, developments in reasoning, agent architectures, and analysis strategies will probably be essential. Strengthening interdisciplinary collaboration can be certain that AI-driven brokers speed up scientific discovery whereas sustaining reproducibility, verifiability, and integrity.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 80k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.