As AI adoption will increase in digital infrastructure, enterprises and builders face mounting stress to steadiness computational prices with efficiency, scalability, and adaptableness. The fast development of enormous language fashions (LLMs) has opened new frontiers in pure language understanding, reasoning, and conversational AI. Nonetheless, their sheer measurement and complexity usually introduce inefficiencies that inhibit deployment at scale. On this dynamic panorama, the query stays: Can AI architectures evolve to maintain excessive efficiency with out ballooning compute overhead or monetary prices? Enter the subsequent chapter in NVIDIA’s innovation saga, an answer that seeks to optimize this tradeoff whereas increasing AI’s practical boundaries.
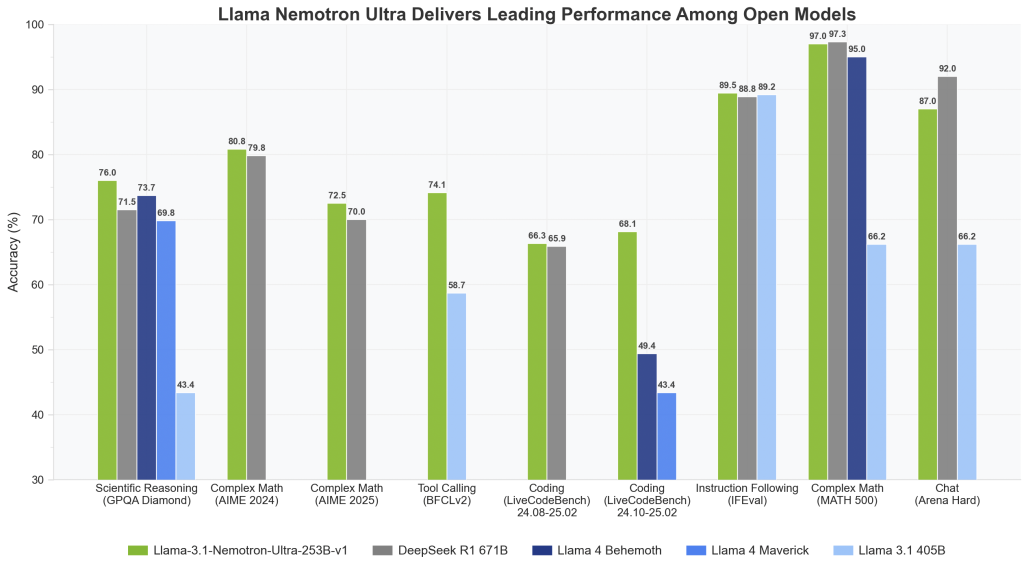
NVIDIA launched the Llama-3.1-Nemotron-Extremely-253B-v1, a 253-billion parameter language mannequin representing a major leap in reasoning capabilities, structure effectivity, and manufacturing readiness. This mannequin is a part of the broader Llama Nemotron Assortment and is immediately derived from Meta’s Llama-3.1-405B-Instruct structure. The 2 different small fashions, part of this sequence, are Llama-3.1-Nemotron-Nano-8B-v1 and Llama-3.3-Nemotron-Tremendous-49B-v1. Designed for industrial and enterprise use, Nemotron Extremely is engineered to assist duties starting from instrument use and retrieval-augmented era (RAG) to multi-turn dialogue and complicated instruction-following.
The mannequin’s core is a dense decoder-only transformer construction tuned utilizing a specialised Neural Structure Search (NAS) algorithm. In contrast to conventional transformer fashions, the structure employs non-repetitive blocks and numerous optimization methods. Amongst these improvements is the skip consideration mechanism, the place consideration modules in sure layers are both skipped completely or changed with easier linear layers. Additionally, the Feedforward Community (FFN) Fusion method merges sequences of FFNs into fewer, wider layers, considerably decreasing inference time whereas sustaining efficiency.
This finely tuned mannequin helps a 128K token context window, permitting it to ingest and purpose over prolonged textual inputs, making it appropriate for superior RAG programs and multi-document evaluation. Furthermore, Nemotron Extremely suits inference workloads onto a single 8xH100 node, which marks a milestone in deployment effectivity. Such compact inference functionality dramatically reduces information middle prices and enhances accessibility for enterprise builders.
NVIDIA’s rigorous multi-phase post-training course of consists of supervised fine-tuning on duties like code era, math, chat, reasoning, and power calling. That is adopted by reinforcement studying (RL) utilizing Group Relative Coverage Optimization (GRPO), an algorithm tailor-made to fine-tune the mannequin’s instruction-following and dialog capabilities. These extra coaching layers be certain that the mannequin performs properly on benchmarks and aligns with human preferences throughout interactive periods.
Constructed with manufacturing readiness in thoughts, Nemotron Extremely is ruled by the NVIDIA Open Mannequin License. Its launch has been accompanied by different sibling fashions in the identical household, together with Llama-3.1-Nemotron-Nano-8B-v1 and Llama-3.3-Nemotron-Tremendous-49B-v1. The discharge window, between November 2024 and April 2025, ensured the mannequin leveraged coaching information up till the tip of 2023, making it comparatively up-to-date in its data and context.
A number of the Key Takeaways from the discharge of Llama-3.1-Nemotron-Extremely-253B-v1 embrace:
- Effectivity-First Design: Utilizing NAS and FFN fusion, NVIDIA lowered mannequin complexity with out compromising accuracy, reaching superior latency and throughput.
- 128K Token Context Size: The mannequin can course of massive paperwork concurrently, boosting RAG and long-context comprehension capabilities.
- Prepared for Enterprise: The mannequin is right for industrial chatbots and AI agent programs as a result of it’s simple to deploy on an 8xH100 node and follows directions properly.
- Superior High-quality-Tuning: RL with GRPO and supervised coaching throughout a number of disciplines ensures a steadiness between reasoning energy and chat alignment.
- Open Licensing: The NVIDIA Open Mannequin License helps versatile deployment, whereas neighborhood licensing encourages collaborative adoption.
Try the Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 85k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.





