Autoregressive (AR) fashions have made important advances in language era and are more and more explored for picture synthesis. Nonetheless, scaling AR fashions to high-resolution photographs stays a persistent problem. Not like textual content, the place comparatively few tokens are required, high-resolution photographs necessitate hundreds of tokens, resulting in quadratic progress in computational value. In consequence, most AR-based multimodal fashions are constrained to low or medium resolutions, limiting their utility for detailed picture era. Whereas diffusion fashions have proven robust efficiency at excessive resolutions, they arrive with their very own limitations, together with advanced sampling procedures and slower inference. Addressing the token effectivity bottleneck in AR fashions stays an vital open drawback for enabling scalable and sensible high-resolution picture synthesis.
Meta AI Introduces Token-Shuffle
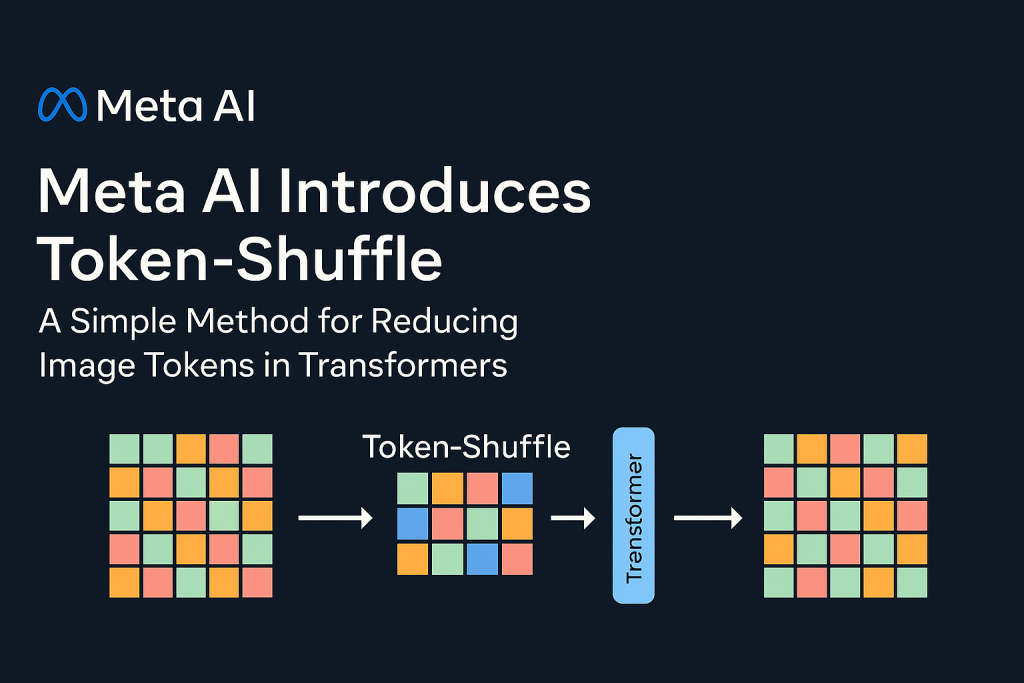
Meta AI introduces Token-Shuffle, a way designed to scale back the variety of picture tokens processed by Transformers with out altering the basic next-token prediction attain. The important thing perception underpinning Token-Shuffle is the popularity of dimensional redundancy in visible vocabularies utilized by multimodal giant language fashions (MLLMs). Visible tokens, usually derived from vector quantization (VQ) fashions, occupy high-dimensional areas however carry a decrease intrinsic info density in comparison with textual content tokens. Token-Shuffle exploits this by merging spatially native visible tokens alongside the channel dimension earlier than Transformer processing and subsequently restoring the unique spatial construction after inference. This token fusion mechanism permits AR fashions to deal with larger resolutions with considerably decreased computational value whereas sustaining visible constancy.

Technical Particulars and Advantages
Token-Shuffle consists of two operations: token-shuffle and token-unshuffle. Throughout enter preparation, spatially neighboring tokens are merged utilizing an MLP to type a compressed token that preserves important native info. For a shuffle window measurement sss, the variety of tokens is decreased by an element of s2s^2s2, resulting in a considerable discount in Transformer FLOPs. After the Transformer layers, the token-unshuffle operation reconstructs the unique spatial association, once more assisted by light-weight MLPs.
By compressing token sequences throughout Transformer computation, Token-Shuffle allows the environment friendly era of high-resolution photographs, together with these at 2048×2048 decision. Importantly, this strategy doesn’t require modifications to the Transformer structure itself, nor does it introduce auxiliary loss capabilities or pretraining of extra encoders.
Moreover, the strategy integrates a classifier-free steerage (CFG) scheduler particularly tailored for autoregressive era. Fairly than making use of a hard and fast steerage scale throughout all tokens, the scheduler progressively adjusts steerage power, minimizing early token artifacts and bettering text-image alignment.
Outcomes and Empirical Insights
Token-Shuffle was evaluated on two main benchmarks: GenAI-Bench and GenEval. On GenAI-Bench, utilizing a 2.7B parameter LLaMA-based mannequin, Token-Shuffle achieved a VQAScore of 0.77 on “laborious” prompts, outperforming different autoregressive fashions akin to LlamaGen by a margin of +0.18 and diffusion fashions like LDM by +0.15. Within the GenEval benchmark, it attained an general rating of 0.62, setting a brand new baseline for AR fashions working within the discrete token regime.
Massive-scale human analysis additional supported these findings. In comparison with LlamaGen, Lumina-mGPT, and diffusion baselines, Token-Shuffle confirmed improved alignment with textual prompts, decreased visible flaws, and better subjective picture high quality normally. Nonetheless, minor degradation in logical consistency was noticed relative to diffusion fashions, suggesting avenues for additional refinement.
When it comes to visible high quality, Token-Shuffle demonstrated the aptitude to supply detailed and coherent 1024×1024 and 2048×2048 photographs. Ablation research revealed that smaller shuffle window sizes (e.g., 2×2) supplied one of the best trade-off between computational effectivity and output high quality. Bigger window sizes offered extra speedups however launched minor losses in fine-grained element.

Conclusion
Token-Shuffle presents a simple and efficient technique to deal with the scalability limitations of autoregressive picture era. By leveraging the inherent redundancy in visible vocabularies, it achieves substantial reductions in computational value whereas preserving, and in some instances bettering, era high quality. The tactic stays absolutely appropriate with present next-token prediction frameworks, making it simple to combine into customary AR-based multimodal techniques.
The outcomes reveal that Token-Shuffle can push AR fashions past prior decision limits, making high-fidelity, high-resolution era extra sensible and accessible. As analysis continues to advance scalable multimodal era, Token-Shuffle supplies a promising basis for environment friendly, unified fashions able to dealing with textual content and picture modalities at giant scales.
Try the Paper. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 90k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.