Giant language fashions at the moment are central to numerous functions, from coding to educational tutoring and automatic assistants. Nevertheless, a essential limitation persists in how these fashions are designed; they’re educated on static datasets that change into outdated over time. This creates a basic problem as a result of the language fashions can not replace their information or validate responses towards contemporary, real-world information. Because of this, whereas these fashions reveal robust efficiency on reasoning duties or structured queries, their solutions can nonetheless embrace fabricated or out of date info, decreasing their reliability in real-world utilization. To take care of credibility, particularly for functions requiring up to date information similar to information, analysis, or product critiques, fashions should work together with exterior information sources in a well timed and cost-efficient method.
The core downside lies in educating these fashions to successfully retrieve and incorporate exterior info. Whereas fine-tuned pretraining helps develop a powerful baseline understanding, the capability to conduct significant, dynamic searches is lacking. Equipping language fashions with this capability introduces sensible constraints. Search engines like google used for exterior info retrieval present various doc high quality that introduces inconsistency in mannequin coaching. Furthermore, integrating reinforcement studying to simulate real-world looking requires large-scale interactions with dwell APIs, operating up a whole lot of 1000’s of calls, which turns into prohibitively costly. This ends in a bottleneck for educational analysis and business deployment, the place value and coaching scalability are essential.
Numerous strategies have been developed to boost language fashions’ search and retrieval capabilities. Some early strategies relied on prompt-based directions that guided the mannequin via processes like producing sub-queries or managing multi-step searches. These strategies, nevertheless, closely relied on handbook tuning and sometimes required in depth computational assets to make sure constant outputs. Different approaches leaned on supervised fine-tuning for smaller fashions to carry out extra focused retrieval, with fashions like Self-RAG and RetroLLM rising on this area. There have additionally been experiments with strategies like Monte Carlo Tree Search to broaden doable reply paths throughout inference dynamically. Reinforcement learning-based options like Search-R1 and DeepResearcher allowed fashions to work together straight with actual search engines like google and yahoo, providing a coaching expertise nearer to how customers behave. Nevertheless, these improvements nonetheless endure from both complexity, excessive computational demand, or monetary value on account of dwell interplay constraints.
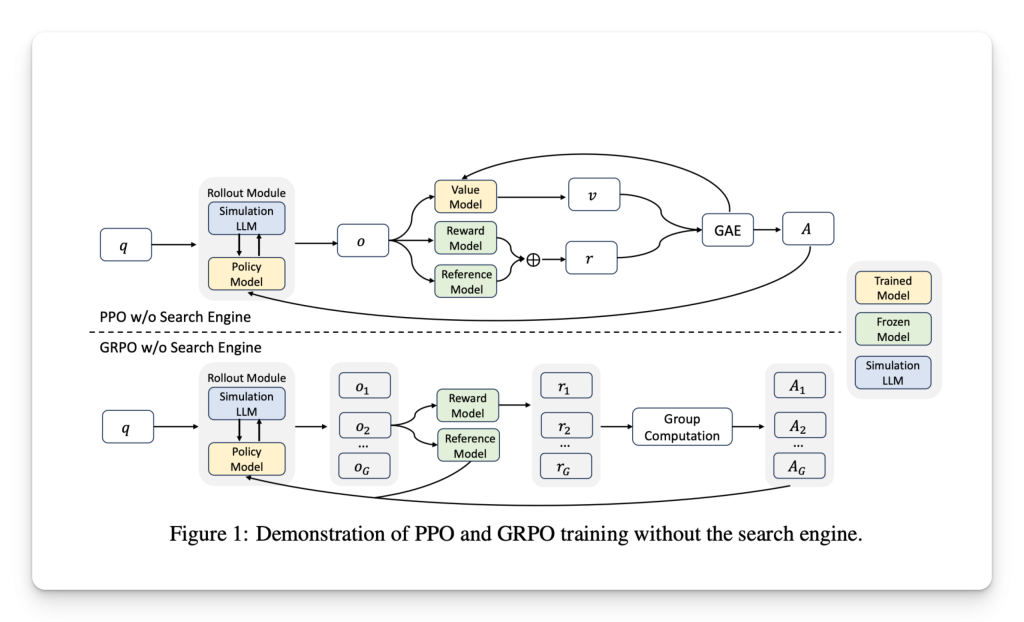
Researchers from Tongyi Lab at Alibaba Group launched an progressive answer known as ZeroSearch. This reinforcement studying framework removes the necessity for dwell API-based search totally. As an alternative, it makes use of one other language mannequin to simulate the habits of a search engine. The simulation mannequin is fine-tuned via supervised coaching to generate paperwork that both assist or mislead the coverage mannequin, relying on whether or not the content material is designed to be related or noisy. This enables full management over the doc high quality and price whereas enabling a practical retrieval coaching expertise. A key innovation lies in utilizing curriculum-based studying throughout coaching, which suggests steadily introducing more durable retrieval duties by adjusting how a lot noise is current within the generated paperwork. This development helps the coverage mannequin develop resilience and higher reasoning expertise over time with out ever making an actual search question.

The construction of ZeroSearch includes distinct phases within the reasoning course of. The mannequin first thinks internally utilizing designated tags, then generates queries if it determines that extra info is required. Lastly, it outputs a solution solely when enough context is acquired. This structured strategy enforces readability in decision-making and has been proven to enhance transparency and reply high quality. A minimal change in prompts guides doc era for the simulated search engine that controls whether or not the doc seems useful or deceptive. The simulated LLM is fine-tuned utilizing interplay information the place every retrieval trajectory is labeled primarily based on the correctness of the ultimate reply. The coverage mannequin is taught to deal with easy and complicated search circumstances by systematically various doc high quality. A efficiency scaling operate determines how a lot noise is launched at every coaching stage, growing the mannequin’s capability to navigate uncertainty over time.
A 3-billion parameter mannequin was in a position to simulate the retrieval course of for coaching functions successfully. The outcomes grew to become significantly notable with bigger fashions. A 7B retrieval module was carried out at a degree similar to Google Search relating to response high quality. A 14B mannequin even surpassed Google Search benchmarks. ZeroSearch additionally confirmed flexibility, functioning successfully throughout base and instruction-tuned LLMs of various sizes. It integrates properly with a spread of reinforcement studying algorithms, together with PPO, GRPO, and Reinforce++, and it makes use of a reward design primarily based on the F1 rating quite than actual match to discourage the mannequin from producing excessively lengthy solutions simply to extend key phrase overlap. Moreover, ZeroSearch makes use of a masking mechanism throughout backpropagation to make sure that gradients are solely computed on the coverage mannequin’s outputs, stabilizing coaching with out sacrificing efficiency.

The analysis demonstrates a transparent and environment friendly various to real-time search engine reliance. Utilizing simulation-driven doc era removes the necessity for high-cost APIs, and the standard of coaching enter is managed with precision. The tactic additionally boosts mannequin reasoning functionality by introducing progressive noise and uncertainty, successfully mimicking how real-world information retrieval may fail or mislead. The coverage mannequin is educated to extract probably the most helpful info. These traits make ZeroSearch a scalable and sensible answer for commercial-grade functions.

This strategy efficiently identifies and addresses the dual challenges of doc high quality variability and financial value which have restricted real-time search integration in language mannequin coaching. It combines doc simulation, structured interplay, and reinforcement studying to make sure effectiveness and scalability. By relying solely on simulated information era, the researchers achieved superior or comparable outcomes to current strategies whereas eradicating all dependency on pricey APIs.
A number of Key Takeaways from the Analysis embrace the next:
- A 3B mannequin simulated lifelike doc retrieval successfully with zero API value.
- A 7B retrieval module matched Google Search efficiency in benchmark assessments.
- The 14B mannequin exceeded actual search engine efficiency.
- Reinforcement studying was carried out with a curriculum-based rollout that steadily launched noise.
- A simulation LLM generated each related and noisy paperwork by way of light-weight supervised fine-tuning.
- Structured interplay phases (
, , ) improved mannequin readability and accuracy. - F1-based rewards discouraged reward hacking by penalizing irrelevant reply size.
- Suitable with main RL algorithms together with PPO, GRPO, and Reinforce++.
- Coaching was stabilized utilizing a gradient masking mechanism to forestall instability from simulated tokens.
Try the Paper and Mannequin on Hugging Face. Additionally, don’t neglect to comply with us on Twitter.
Right here’s a short overview of what we’re constructing at Marktechpost:
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.