Knowledge is in every single place and transferring sooner than ever earlier than. If you’re processing logs from thousands and thousands of IoT gadgets, monitoring buyer conduct on an e-commerce website, or monitoring inventory market modifications in actual time, your potential to combine and course of this information shortly and effectively can imply the distinction between your corporation succeeding or failing.
Spark Structured Streaming turns out to be useful right here. The mixture of scalability supplied by cloud companies and the flexibility to deal with real-time information streams makes it a robust software for optimizing integration workflows. Let’s examine how these two applied sciences can be utilized to design sturdy, high-performing information pipelines and learn how to take care of the precise world situation of coping with steady information.
Understanding Spark Structured Streaming
Earlier than diving in, let’s shortly recap Spark Structured Streaming. This software is constructed on high of the favored Apache Spark and is created particularly for stream processing. Spark Structured Streaming is completely different from conventional methods that course of information in batches and makes use of a micro-batch strategy to course of information in actual time. In different phrases, Spark processes information in small items, which permits it to deal with massive streams of knowledge on the identical time with out struggling efficiency or latency points.
Spark Structured Streaming is gorgeous in that it makes use of the identical DataFrame and Dataset APIs that we use in batch processing, making it simpler for builders who already know Spark. No matter whether or not you’re processing a gradual stream of knowledge from IoT sensors or logs from internet servers, Spark can do all of it in the identical method.
The truth that it’s fault-tolerant actually makes this so highly effective. Spark retains monitor of the information in case one thing goes fallacious mid-stream and might get well from the place it left off with out dropping any information, and that is known as checkpointing. As well as, Spark’s scalability signifies that as the quantity of knowledge will increase, the system scales throughout a number of machines or nodes with ease.
The Challenges of Actual-Time Knowledge Integration
Now, earlier than we dig deeper into how Spark and cloud companies resolve integration issues, let’s pause for a second and take into consideration what challenges you face whenever you work with real-time information.
1. Knowledge Selection
Knowledge streams are in every single place: JSON, CSV, logs, sensor readings, you title it. It’s no straightforward feat to combine and course of this information constantly throughout a number of methods. The construction of every supply could also be completely different, and mixing them generally is a headache for information engineers.
2. Dealing with Excessive Velocity
One other problem is how briskly information is available in. Think about an e-commerce website that has to serve hundreds of person interactions per second or a sensible metropolis that’s monitoring site visitors circulation from lots of of hundreds of sensors. In case your system can’t deal with the rate, you could possibly run into bottlenecks, delays, and inaccuracies in your information processing.
3. Scalability
The system has to develop as information grows. A small system that may deal with information in actual time will get swamped shortly as the quantity of knowledge will increase. An important factor is that your information pipeline can scale routinely with none handbook intervention.
4. Fault Tolerance
Uptime is crucial in real-time methods. The system ought to be capable to get well from a failure with out lack of information or inconsistency. Lacking priceless insights or corrupting the whole information stream is a single hiccup in processing.
Spark Structured Streaming: The way it Solves These Issues
1. Unified API for Each Batch and Streaming
The foremost benefit of Spark Structured Streaming is that it permits us to do batch processing and stream processing via the identical API. No matter whether or not you’re processing information in batches (e.g. logs from the previous hour) or streaming it (e.g. person exercise information from an internet site), the identical instruments and strategies are relevant.
The unified API makes improvement simpler for builders and helps them work extra effectively and hold workflows constant. Additionally, it doesn’t require you to be taught model new applied sciences to maneuver from batch to real-time processing.
2. Fault Tolerance and Restoration
The checkpointing mechanism of Spark is not going to lose any information if a failure happens. It information the progress of every batch and saves the state of the stream in order that if a failure occurs, Spark can proceed to course of from the place it left off. With this built-in restoration characteristic, downtime is minimized, and your integration workflows are made resilient to failures.
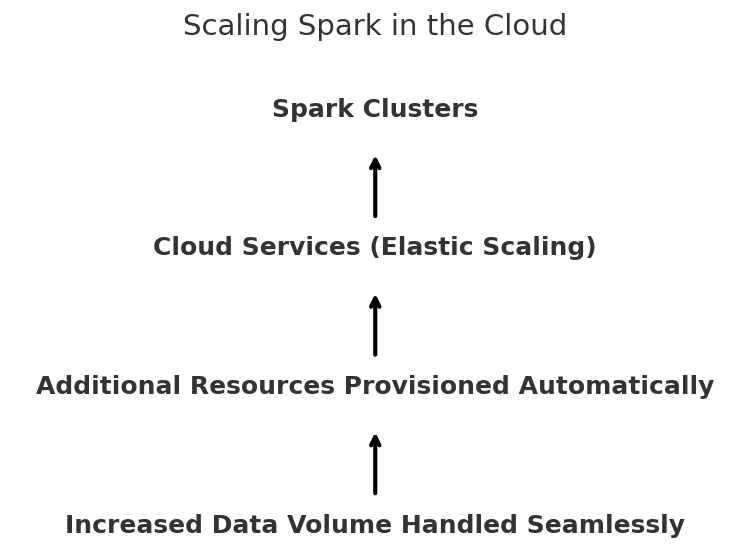
3. Horizontal Scalability
Actual-time information integration usually requires heavy processing energy. The system ought to develop in accordance with the quantity of knowledge. Spark is a distributed system and might scale horizontally, which implies you may add extra nodes to your cluster to deal with extra load with out breaking a sweat. When the information scales up, it routinely divides the work amongst obtainable nodes in order that processing is quick and environment friendly.
4. Actual-Time Knowledge Transformation
Structured Streaming is not only about ingesting information; Spark can even remodel it on the fly. Spark lets you course of information in actual time, whether or not you’re cleansing information, enriching it with information from different sources, or making use of enterprise guidelines. It is a essential characteristic for integration workflows as a result of it signifies that the information being processed is instantly helpful with out having to attend for batch jobs to finish.
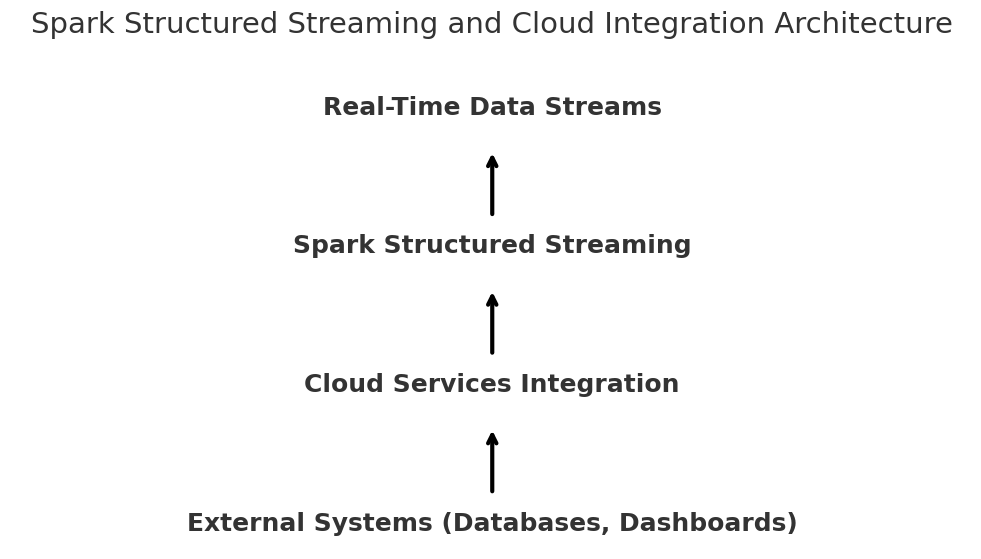
How Cloud Companies Take Spark to the Subsequent Stage
Spark is a robust software itself, however cloud companies add to this energy by offering scalable infrastructure, straightforward administration, and straightforward integration with different companies. Spark Structured Streaming is complemented by cloud platforms within the following methods.
1. Elastic Scalability
Elastic scaling is a trademark of cloud environments — sources could be added or taken away as wanted. For instance, in case your information stream will increase (say, due to a advertising marketing campaign or a product launch), the cloud can routinely allocate extra sources to Spark. Which means you’ll not encounter any slowdowns, even within the busiest site visitors hours.
2. Managed Infrastructure
Managed Spark clusters can be found from cloud suppliers, so there’s no want to fret about infrastructure administration or {hardware} failures. It saves you effort and time, so you may spend your time constructing your integration workflows, and the cloud handles the underlying infrastructure.
3. Excessive Availability and Reliability
Excessive availability is the design of the cloud companies. In case of failure of 1 server or node, the cloud routinely strikes the load to a different wholesome server to keep up the uptime. That is crucial for real-time information workflows the place even a small interruption can result in information loss or delay.
4. Integration with Different Cloud Companies
Spark could be simply built-in with an enormous set of instruments and companies which might be obtainable on cloud platforms. If you happen to want someplace to retailer your information, you’re in the precise place. You must use cloud storage options like Amazon S3 or Google Cloud Storage. Desire a messaging system for dealing with real-time occasions? Pair Spark with Apache Kafka or Amazon Kinesis. The mixture of those companies is seamless and creates a whole ecosystem to your information pipelines.
Actual-World Use Circumstances of Spark Structured Streaming
Let’s collect all this along with some real-world examples of how Spark Structured Streaming and cloud companies are getting used to resolve information integration issues.
1. Actual-Time Monetary Knowledge Processing
Actual-time information is crucial to monetary establishments to detect fraud and to make quick buying and selling selections. With Spark Structured Streaming and companies within the cloud, they’ll course of hundreds of transactions per second, flagging suspicious exercise in actual time. They’re able to scale up throughout peak buying and selling hours to have the ability to address the elevated information circulation with none delay.
2. IoT Knowledge in Good Cities
Knowledge from the site visitors lights, parking meters, and different infrastructure in sensible cities is generated in huge quantities by sensors. Actual-time evaluation of this information is feasible with Spark Structured Streaming, and cities can optimize site visitors circulation, cut back congestion, and enhance public companies. The cloud companies assure that the extra information doesn’t burden the infrastructure because the variety of sensors will increase.
3. E-commerce Buyer Exercise
Actual-time buyer conduct monitoring is completed on e-commerce platforms to offer personalised experiences and enhance conversion charges. These platforms can course of streams of person actions (akin to clicks, searches, purchases) and ship real-time personalised product suggestions or alter stock in actual time utilizing Spark Structured Streaming. This method can scale to thousands and thousands of concurrent customers at peak purchasing instances as a result of cloud companies.
Conclusion
In the present day, having the ability to course of and combine real-time information is changing into more and more vital. Structured Streaming on Spark lets you simply take care of real-time information streams, and the cloud companies offer you the scalability and suppleness to scale your integration workflows with your corporation.
Utilizing Spark and cloud infrastructure, you may construct information pipelines which might be quick, dependable, and scalable to any information problem the trendy information world can throw your method. This mixture will optimize your workflows and ensure your system stays responsive and environment friendly.