Over the previous decade, cellphones have integrated more and more highly effective purpose-specific accelerators together with GPUs and not too long ago, extra highly effective NPUs (Neural Processing Items). By accelerating your AI fashions on cellular GPUs and NPUs, you’ll be able to pace up your fashions by as much as 25x in comparison with CPU whereas additionally lowering energy consumption by as much as 5x. Nonetheless, unlocking these excellent efficiency advantages has confirmed difficult for many builders, because it requires wrangling HW-specific APIs in case of GPU inference or wrangling vendor-specific SDKs, codecs, and runtimes for NPU inference.
Listening to your suggestions, the Google AI Edge group is worked up to announce a number of enhancements to LiteRT fixing the challenges above, and accelerating AI on cellular extra simply with elevated efficiency. Our new launch features a new LiteRT API making on-device ML inference simpler than ever, our newest cutting-edge GPU acceleration, new NPU help co-developed with MediaTek and Qualcomm (open for early entry), and superior inference options to maximise efficiency for on-device purposes. Let’s dive in!
MLDrift: Greatest GPU Acceleration But
GPUs have at all times been on the coronary heart of LiteRT’s acceleration story, offering the broadest help and most constant efficiency enchancment. MLDrift, our newest model of GPU acceleration, pushes the bar even additional with sooner efficiency and enhancements to help fashions of a considerably bigger measurement by means of:
- Smarter Knowledge Group: MLDrift arranges information in a extra environment friendly manner by utilizing optimized tensor layouts and storage sorts particularly tailor-made for a way GPUs course of information, lowering reminiscence entry time and rushing up AI calculations.
- Workgroup Optimization: Sensible computation based mostly on context (stage) and useful resource constraints
- Improved Knowledge Dealing with: Streamlining the way in which the accelerator receives and sends out tensor information to scale back overhead in information switch and conversion optimizing for information locality.
This leads to considerably sooner efficiency than CPUs, than earlier variations of our TFLite GPU delegate, and even different GPU enabled frameworks notably for CNN and Transformer fashions.
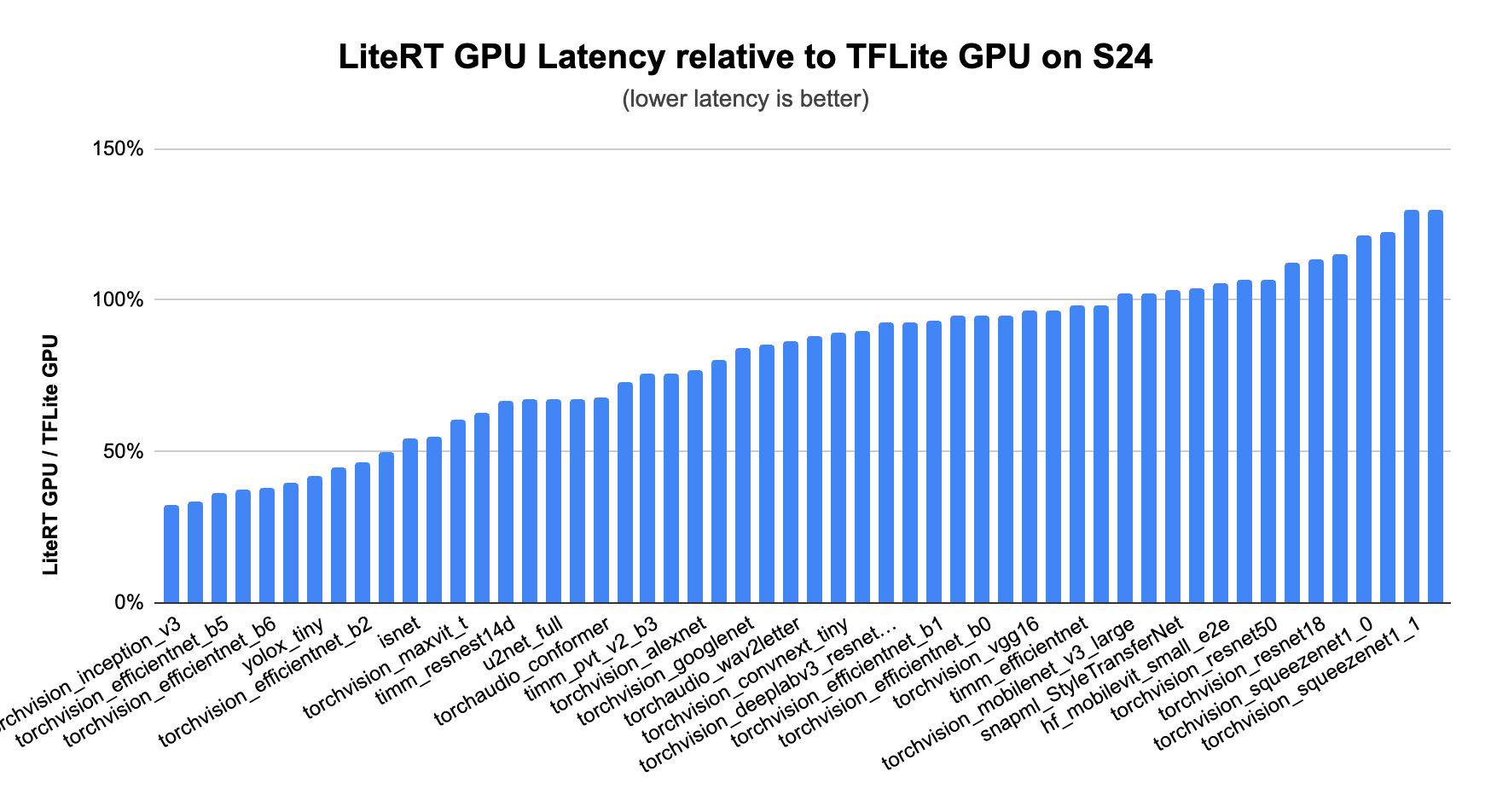
Determine: Inference latency per mannequin of LiteRT GPU in comparison with TFLite GPU, measured on Samsung 24.
Discover examples in our documentation and provides GPU acceleration a attempt in the present day.
NPUs, AI particular accelerators, have gotten more and more widespread in flagship telephones. They can help you run AI fashions rather more effectively, and in lots of circumstances a lot sooner. In our inner testing in comparison with CPUs this acceleration will be as much as 25x sooner, and 5x extra energy environment friendly. (Could 2025, based mostly on inner testing)
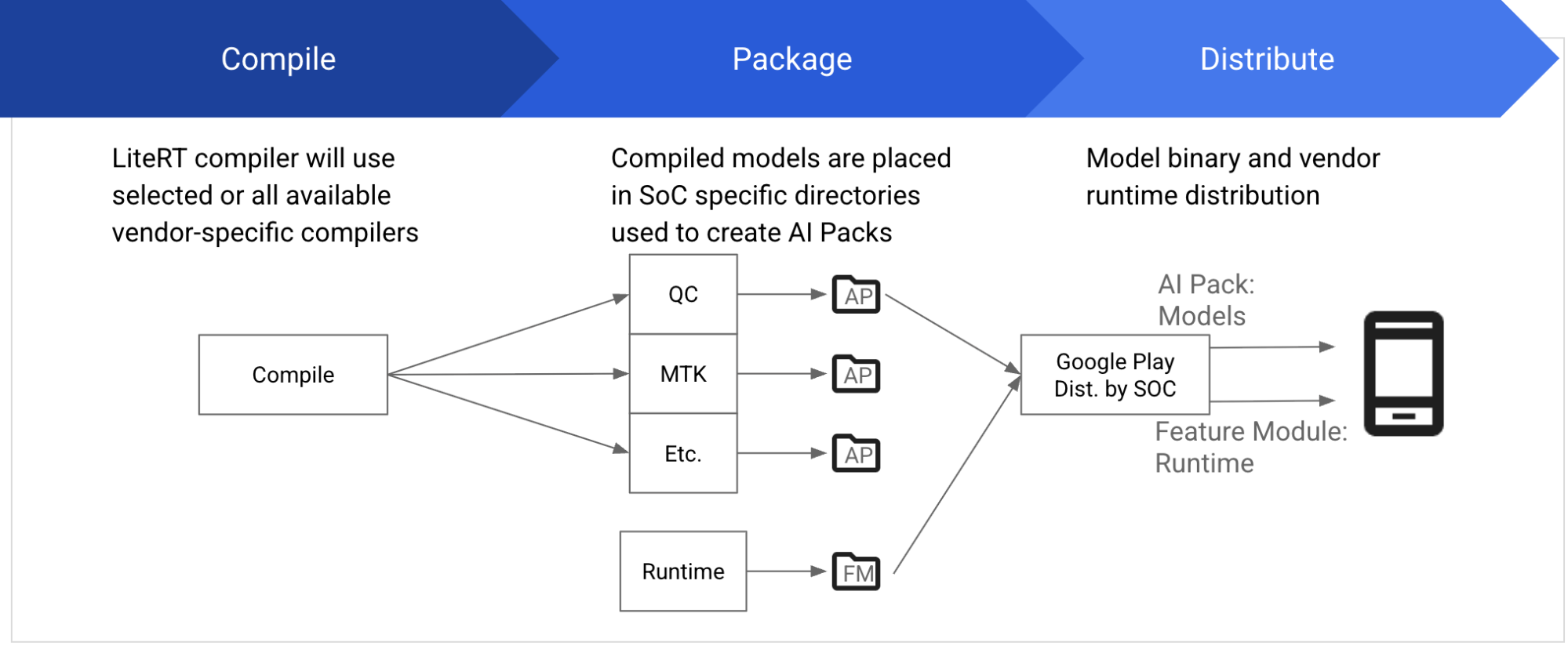
Usually, every vendor supplies their very own SDKs, together with compilers, runtime, and different dependencies, to compile and execute fashions on their SoCs. The SDK should exactly match the particular SoC model and requires correct obtain and set up. LiteRT now supplies a uniform strategy to develop and deploy fashions on NPUs, abstracting away all these complexities.
- Vendor compiler distribution: When putting in the LiteRT PyPI package deal, we are going to routinely obtain the seller SDKs for compiling fashions.
- Mannequin and vendor runtime distribution: The compiled mannequin and SoC runtime will should be distributed with the app. As a developer you’ll be able to deal with this distribution your self, or you’ll be able to have Google Play distribute them for you. In our instance code you’ll be able to see easy methods to use AI Packs and Function Supply to ship the proper mannequin and runtime to the proper system.
We’re excited to companion with MediaTek and Qualcomm to permit builders to speed up all kinds of basic ML fashions, reminiscent of imaginative and prescient, audio, and NLP fashions, on MediaTek and Qualcomm NPUs. Elevated mannequin and area help will proceed over the approaching 12 months.
This function is offered in non-public preview. For early entry apply right here.
Simplified GPU and NPU {Hardware} Acceleration
We’ve made GPUs and NPUs simpler than ever to make use of by simplifying the method within the newest model of the LiteRT APIs. With the newest adjustments, we’ve simplified the setup considerably with the flexibility to specify the goal backend as an possibility. For example, that is how a developer would specify GPU acceleration:
// 1. Load mannequin.
auto mannequin = *Mannequin::Load("mymodel.tflite");
// 2. Create a compiled mannequin focusing on GPU.
auto compiled_model = *CompiledModel::Create(mannequin, kLiteRtHwAcceleratorGpu);C++
As you’ll be able to see, the brand new CompiledModel API significantly simplifies easy methods to specify the mannequin and goal backend(s) for acceleration.
Superior Inference for Efficiency Optimization
Whereas utilizing excessive efficiency backends is useful, optimum efficiency of your software will be hindered by reminiscence, or processor bottlenecks. With the brand new LiteRT APIs, you’ll be able to handle these challenges by leveraging built-in buffer interoperability to remove expensive reminiscence copy operations, and asynchronous execution to make the most of idle processors in parallel.
Seamless Buffer Interoperability
The brand new TensorBuffer API supplies an environment friendly strategy to deal with enter/output information with LiteRT. It permits you to instantly use information residing in {hardware} reminiscence, reminiscent of OpenGL Buffers, as inputs or outputs in your CompiledModel, fully eliminating the necessity for expensive CPU copies.
auto tensor_buffer = *litert::TensorBuffer::CreateFromGlBuffer(tensor_type, opengl_buffer);C++
This considerably reduces pointless CPU overhead and boosts efficiency.
Moreover, the TensorBuffer API permits seamless copy-free conversions between totally different {hardware} reminiscence sorts when supported by the system. Think about effortlessly remodeling information from an OpenGL Buffer to an OpenCL Buffer and even to an Android HardwareBuffer with none intermediate CPU transfers.
This method is essential to dealing with the rising information volumes and demanding efficiency required by more and more advanced AI fashions. Yow will discover examples in our documentation on easy methods to use TensorBuffer.
Asynchronous Execution
Asynchronous execution permits totally different elements of the AI mannequin or impartial duties to run concurrently throughout CPU, GPU, and NPUs permitting you to opportunistically leverage obtainable compute cycles from totally different processors to enhance effectivity and responsiveness. As an example:
- the CPU would possibly deal with information preprocessing
- the GPU might speed up matrix multiplications in a neural community layer, and
- the NPU would possibly effectively handle particular inference duties – all taking place in parallel.
In purposes which require real-time AI interactions, a activity will be initiated on one processor and proceed with different operations on one other. Parallel processing minimizes latency and supplies a smoother, extra interactive consumer expertise. By successfully managing and overlapping computations throughout a number of processors, asynchronous execution maximizes system throughput and ensures that the AI software stays fluid and reactive, even beneath heavy computational masses.
Async execution is applied by utilizing OS-level mechanisms (e.g., sync fences on Android/Linux) permitting one HW accelerator to set off upon the completion of one other HW accelerator instantly with out involving the CPU. This reduces latency (as much as 2x in our GPU async demo) and energy consumption whereas making the pipeline extra deterministic.
Right here is the code snippet displaying async inference with OpenGL buffer enter:
// Create an enter TensorBuffer based mostly on tensor_type that wraps the given OpenGL
// Buffer. env is an LiteRT atmosphere to make use of present EGL show and context.
auto tensor_buffer_from_opengl = *litert::TensorBuffer::CreateFromGlBuffer(env,
tensor_type, opengl_buffer);
// Create an enter occasion and fasten it to the enter buffer. Internally, it
// creates and inserts a fence sync object into the present EGL command queue.
auto input_event = *Occasion::CreateManaged(env, LiteRtEventTypeEglSyncFence);
tensor_buffer_from_opengl.SetEvent(std::transfer(input_event));
// Create the enter and output TensorBuffers…
// Run async inference
compiled_model1.RunAsync(input_buffers, output_buffers);C++
Extra code examples can be found in our documentation on easy methods to leverage async execution.
We encourage you to check out the newest acceleration capabilities and efficiency enchancment methods to carry your customers the absolute best expertise whereas leveraging the newest AI fashions. That can assist you get began, try our pattern app with totally built-in examples of easy methods to use all of the options.
All new LiteRT options talked about on this weblog will be discovered at: https://github.com/google-ai-edge/LiteRT
For extra Google AI Edge information, examine our updates in on-device GenAI and our new AI Edge Portal service for broad protection on-device benchmarking and evals.
Discover this announcement and all Google I/O 2025 updates on io.google beginning Could 22.
Acknowledgements
Thanks to the members of the group, and collaborators for his or her contributions in making the developments on this launch doable: Advait Jain, Alan Kelly, Alexander Shaposhnikov, Andrei Kulik, Andrew Zhang, Akshat Sharma, Byungchul Kim, Chunlei Niu, Chuo-Ling Chang, Claudio Basile, Cormac Brick, David Massoud, Dillon Sharlet, Eamon Hugh, Ekaterina Ignasheva, Fengwu Yao, Frank Ban, Frank Barchard, Gerardo Carranza, Grant Jensen, Henry Wang, Ho Ko, Jae Yoo, Jiuqiang Tang, Juhyun Lee, Julius Kammerl, Khanh LeViet, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Mark Sherwood, Matt Kreileder, Matthias Grundmann, Misha Gutman, Pedro Gonnet, Ping Yu, Quentin Khan, Raman Sarokin, Sachin Kotwani, Steven Toribio, Suleman Shahid, Teng-Hui Zhu, Volodymyr Kysenko, Wai Hon Legislation, Weiyi Wang, Youchuan Hu, Yu-Hui Chen