Tencent’s Hunyuan staff has launched Hunyuan-A13B, a brand new open-source giant language mannequin constructed on a sparse Combination-of-Specialists (MoE) structure. Whereas the mannequin consists of 80 billion whole parameters, solely 13 billion are energetic throughout inference, providing a extremely environment friendly steadiness between efficiency and computational value. It helps Grouped Question Consideration (GQA), 256K context size, and a dual-mode reasoning framework that toggles between quick and gradual pondering.
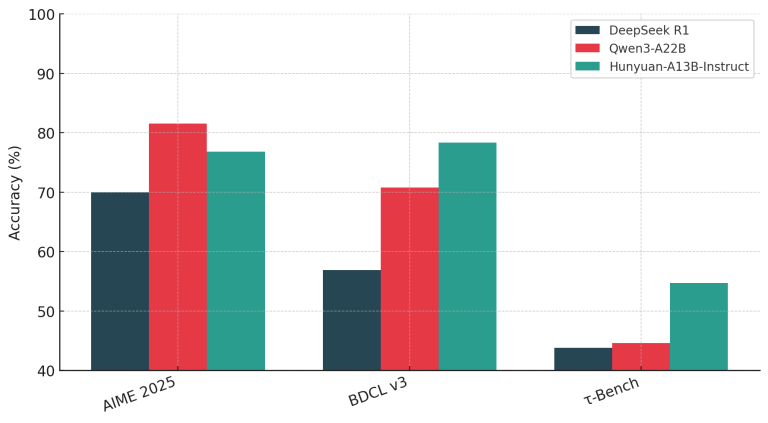
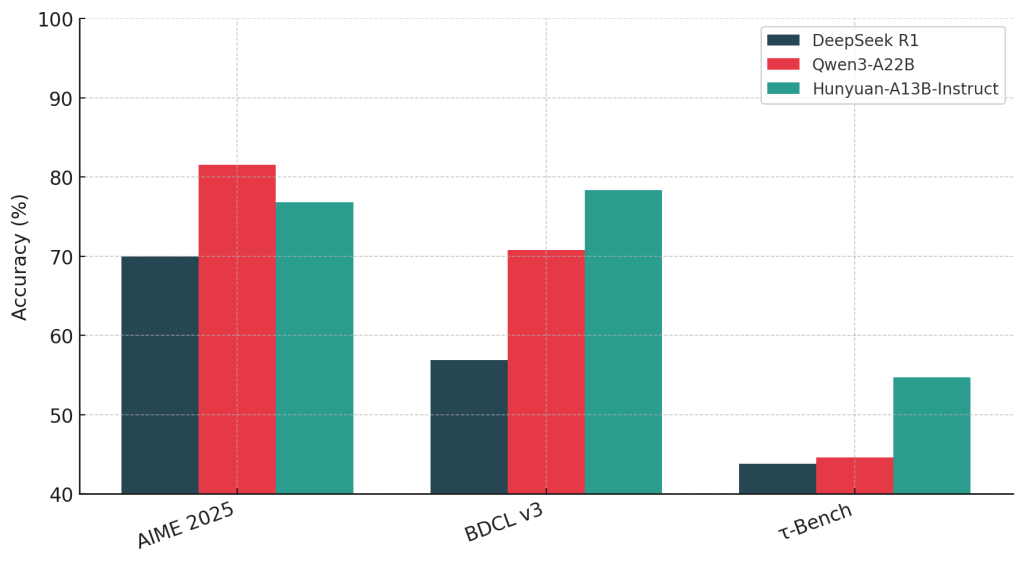
Designed for environment friendly deployment and sturdy reasoning, Hunyuan-A13B achieves top-tier efficiency throughout agentic benchmarks together with BFCL-v3, τ-Bench, C3-Bench, and ComplexFuncBench, usually outperforming bigger fashions in tool-calling and long-context eventualities.
Structure: Sparse MoE with 13B Energetic Parameters
At its core, Hunyuan-A13B follows a fine-grained MoE design comprising 1 shared skilled and 64 non-shared consultants, with 8 consultants activated per ahead cross. This structure, backed by scaling experiments, ensures efficiency consistency whereas conserving inference prices low. The mannequin contains 32 layers, makes use of SwiGLU activations, a vocabulary measurement of 128K, and integrates GQA for enhanced reminiscence effectivity throughout long-context inference.
The mannequin’s MoE setup is paired with an optimized coaching curriculum: a 20T-token pretraining section, adopted by quick annealing and long-context adaptation. This final section scales the context window first to 32K after which to 256K tokens utilizing NTK-aware positional encoding, guaranteeing secure efficiency at giant sequence lengths.
Twin-Mode Reasoning: Quick and Sluggish Pondering
A standout characteristic of Hunyuan-A13B is its dual-mode Chain-of-Thought (CoT) functionality. It helps each a low-latency fast-thinking mode for routine queries and a extra elaborate slow-thinking mode for multi-step reasoning. These modes are managed by a easy tag system: /no suppose for quick inference and /suppose for reflective reasoning. This flexibility permits customers to adapt computational value to activity complexity.
Submit-Coaching: Reinforcement Studying with Job-Particular Reward Fashions
The post-training pipeline of Hunyuan-A13B contains multi-stage supervised fine-tuning (SFT) and reinforcement studying (RL) throughout each reasoning-specific and common duties. The RL levels incorporate outcome-based rewards and tool-specific suggestions, together with sandbox execution environments for code and rule-based checks for brokers.
Within the agent coaching section, the staff synthesized various tool-use eventualities with planner, checker, and power roles, producing over 20,000 format mixtures. This strengthened Hunyuan-A13B’s skill to execute real-world workflows reminiscent of spreadsheet processing, data search, and structured reasoning.

Analysis: State-of-the-Artwork Agentic Efficiency
Hunyuan-A13B reveals robust benchmark outcomes throughout various NLP duties:
- On MATH, CMATH, and GPQA, it scores on par or above bigger dense and MoE fashions.
- It surpasses Qwen3-A22B and DeepSeek R1 in logical reasoning (BBH: 89.1; ZebraLogic: 84.7).
- In coding, it holds its personal with 83.9 on MBPP and 69.3 on MultiPL-E.
- For agent duties, it leads on BFCL-v3 (78.3) and ComplexFuncBench (61.2), validating its tool-usage capabilities.
Lengthy-context comprehension is one other spotlight. On PenguinScrolls, it scores 87.7—simply shy of Gemini 2.5 Professional. On RULER, it sustains excessive efficiency (73.9) even at 64K–128K context, outperforming bigger fashions like Qwen3-A22B and DeepSeek R1 in context resilience.

Inference Optimization and Deployment
Hunyuan-A13B is absolutely built-in with standard inference frameworks like vLLM, SGLang, and TensorRT-LLM. It helps precision codecs reminiscent of W16A16, W8A8, and KV Cache FP8, together with options like Auto Prefix Caching and Chunk Prefill. It achieves as much as 1981.99 tokens/sec throughput on a 32-batch enter (2048 enter, 14336 output size), making it sensible for real-time functions.
Open Supply and Business Relevance
Obtainable on Hugging Face and GitHub, Hunyuan-A13B is launched with permissive open-source licensing. It’s engineered for environment friendly analysis and manufacturing use, particularly in latency-sensitive environments and long-context duties.
By combining MoE scalability, agentic reasoning, and open-source accessibility, Tencent’s Hunyuan-A13B affords a compelling various to heavyweight LLMs, enabling broader experimentation and deployment with out sacrificing functionality.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.