Autoregressive video technology is a quickly evolving analysis area. It focuses on the synthesis of movies frame-by-frame utilizing realized patterns of each spatial preparations and temporal dynamics. In contrast to conventional video creation strategies, which can depend on pre-built frames or handcrafted transitions, autoregressive fashions purpose to generate content material dynamically based mostly on prior tokens. This strategy is much like how giant language fashions predict the following phrase. It gives a possible to unify video, picture, and textual content technology below a shared framework through the use of the structural energy of transformer-based architectures.
One main downside on this house is the best way to precisely seize and mannequin the intrinsic spatiotemporal dependencies in movies. Movies include wealthy constructions throughout each time and house. Encoding this complexity so fashions can predict coherent future frames stays a problem. When these dependencies are usually not modeled properly, it results in damaged body continuity or unrealistic content material technology. Conventional coaching strategies like random masking additionally battle. They usually fail to supply balanced studying indicators throughout frames. When spatial data from adjoining frames leaks, prediction turns into too straightforward.
A number of strategies try to handle this problem by adapting the autoregressive technology pipeline. Nonetheless, they usually deviate from commonplace giant language mannequin constructions. Some use exterior pre-trained textual content encoders, making fashions extra advanced and fewer coherent. Others carry important latency throughout technology with inefficient decoding. Autoregressive fashions like Phenaki and EMU3 attempt to assist end-to-end technology. Regardless of this, they nonetheless battle with efficiency consistency and excessive coaching prices. Methods like raster-scan order or international sequence consideration additionally don’t scale properly to high-dimensional video knowledge.
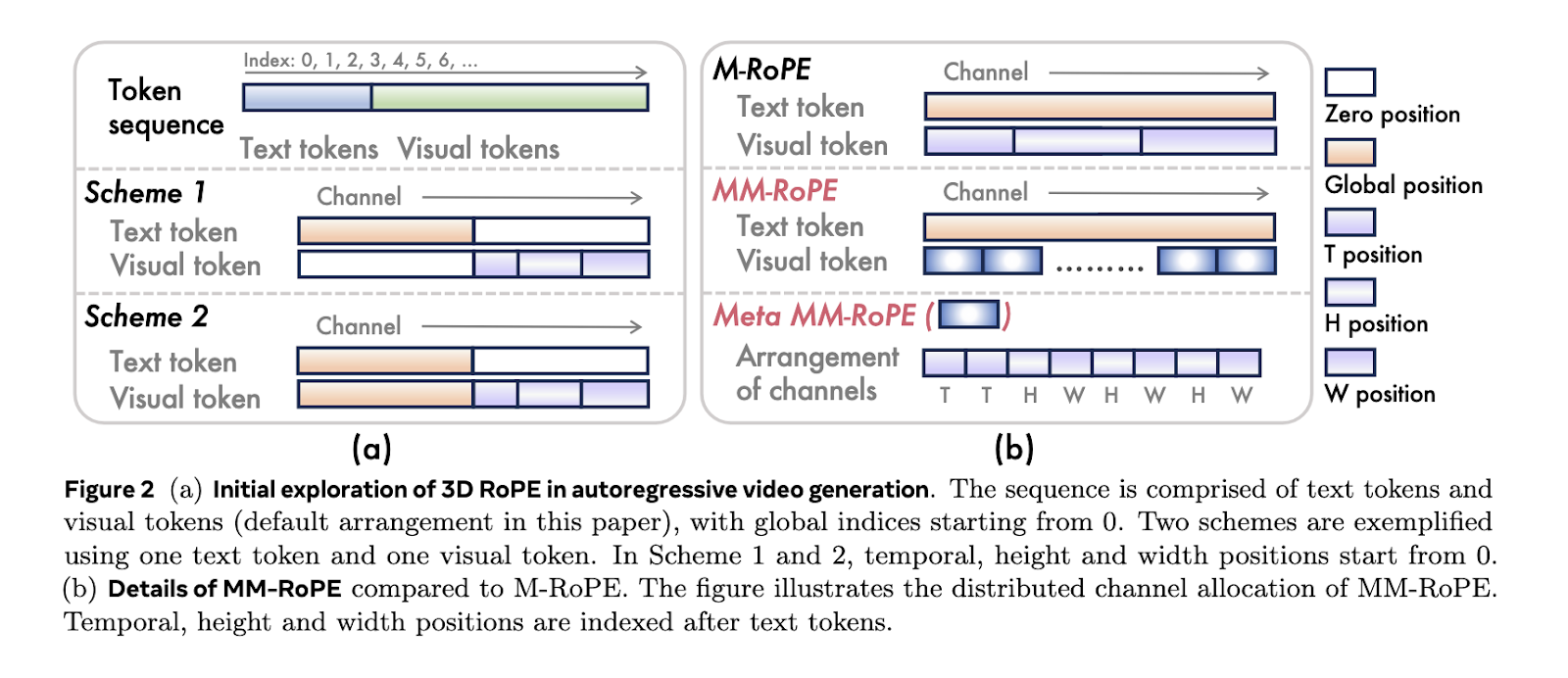
The analysis group from Alibaba Group’s DAMO Academy, Hupan Lab, and Zhejiang College launched Lumos-1. It’s a unified mannequin for autoregressive video technology that stays true to giant language mannequin structure. In contrast to earlier instruments, Lumos-1 eliminates the necessity for exterior encoders and modifications little or no within the unique LLM design. The mannequin makes use of MM-RoPE, or Multi-Modal Rotary Place Embeddings, to handle the problem of modeling video’s three-dimensional construction. The mannequin additionally makes use of a token dependency strategy. This preserves intra-frame bidirectionality and inter-frame temporal causality, which aligns extra naturally with how video knowledge behaves.
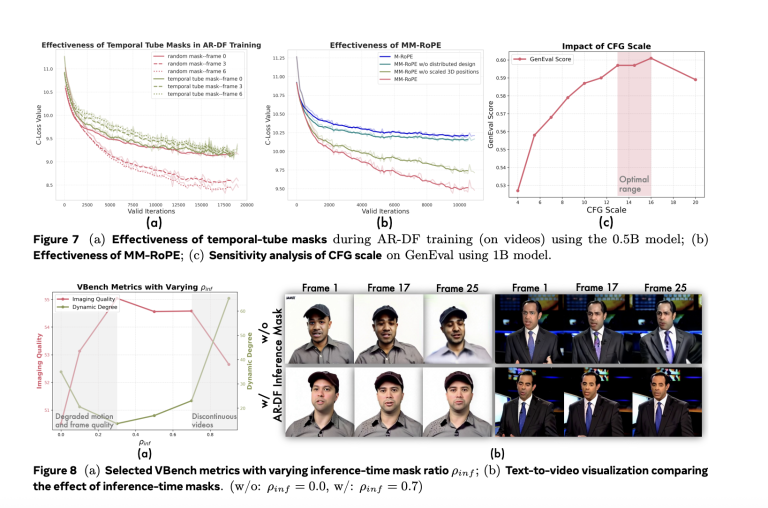
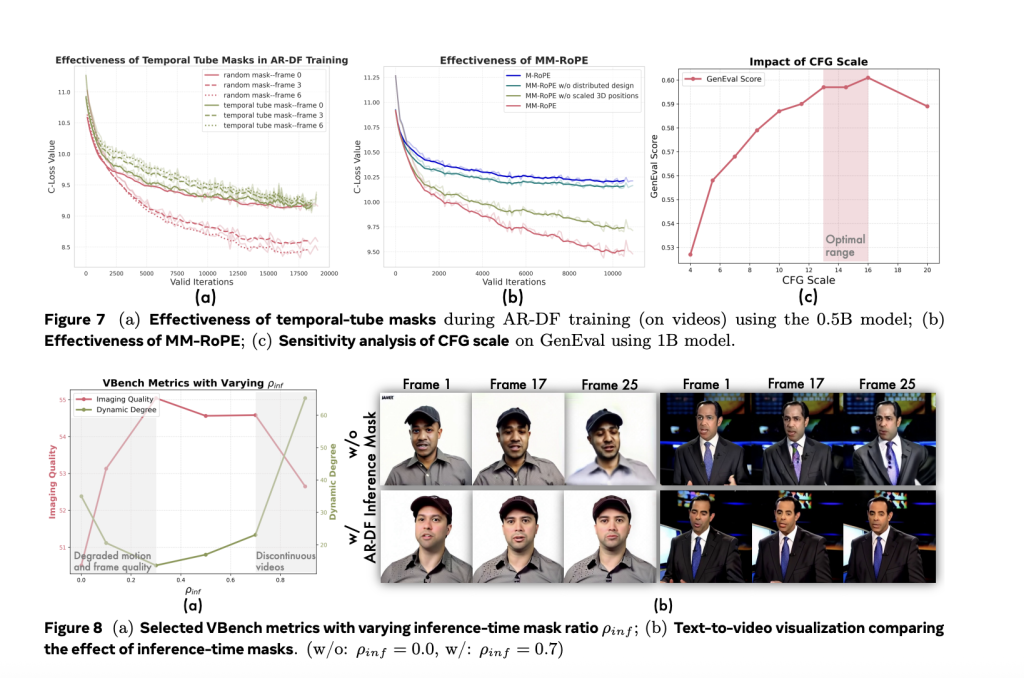
In MM-RoPE, researchers increase present RoPE strategies to stability frequency spectrum for spatial and temporal dimensions. Conventional 3D RoPE misallocates frequency focus, inflicting element loss or ambiguous positional encoding. MM-RoPE restructures allocations in order that temporal, peak, and width every obtain balanced illustration. To handle loss imbalance in frame-wise coaching, Lumos-1 introduces AR-DF, or Autoregressive Discrete Diffusion Forcing. It makes use of temporal tube masking throughout coaching, so the mannequin doesn’t rely an excessive amount of on unmasked spatial information. This ensures even studying throughout the video sequence. The inference technique mirrors the coaching, permitting high-quality body technology with out degradation.
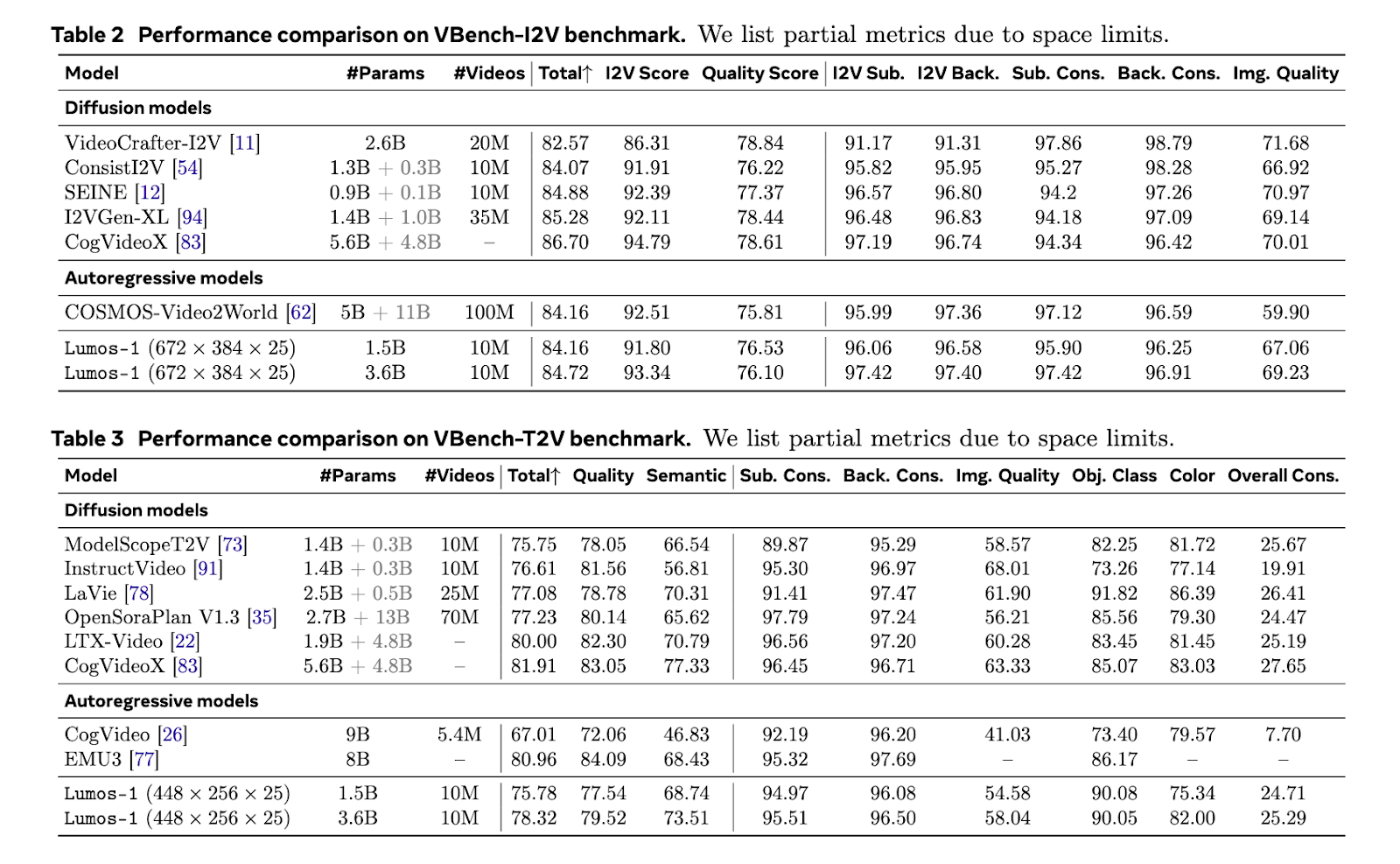
Lumos-1 was educated from scratch on 60 million photos and 10 million movies, utilizing solely 48 GPUs. That is thought of memory-efficient given the coaching scale. The mannequin achieved outcomes akin to prime fashions within the subject. It matched EMU3’s outcomes on GenEval benchmarks. It carried out equivalently to COSMOS-Video2World on the VBench-I2V take a look at. It additionally rivaled OpenSoraPlan’s outputs on the VBench-T2V benchmark. These comparisons present that Lumos-1’s light-weight coaching doesn’t compromise competitiveness. The mannequin helps text-to-video, image-to-video, and text-to-image technology. This demonstrates sturdy generalization throughout modalities.

General, this analysis not solely identifies and addresses core challenges in spatiotemporal modeling for video technology but additionally showcases how Lumos-1 units a brand new commonplace for unifying effectivity and effectiveness in autoregressive frameworks. By efficiently mixing superior architectures with revolutionary coaching, Lumos-1 paves the best way for the following technology of scalable, high-quality video technology fashions and opens up new avenues for future multimodal analysis.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.