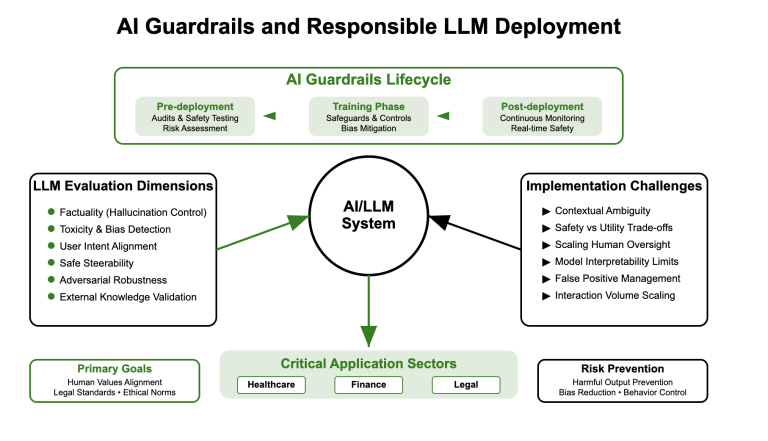
Introduction: The Rising Want for AI Guardrails
As giant language fashions (LLMs) develop in functionality and deployment scale, the chance of unintended habits, hallucinations, and dangerous outputs will increase. The current surge in real-world AI integrations throughout healthcare, finance, training, and protection sectors amplifies the demand for sturdy security mechanisms. AI guardrails—technical and procedural controls making certain alignment with human values and insurance policies—have emerged as a crucial space of focus.
The Stanford 2025 AI Index reported a 56.4% bounce in AI-related incidents in 2024—233 instances in whole—highlighting the urgency for sturdy guardrails. In the meantime, the Way forward for Life Institute rated main AI corporations poorly on AGI security planning, with no agency receiving a score larger than C+.
What Are AI Guardrails?
AI guardrails discuss with system-level security controls embedded throughout the AI pipeline. These are usually not merely output filters, however embrace architectural choices, suggestions mechanisms, coverage constraints, and real-time monitoring. They are often categorized into:
- Pre-deployment Guardrails: Dataset audits, mannequin red-teaming, coverage fine-tuning. For instance, Aegis 2.0 consists of 34,248 annotated interactions throughout 21 safety-relevant classes.
- Coaching-time Guardrails: Reinforcement studying with human suggestions (RLHF), differential privateness, bias mitigation layers. Notably, overlapping datasets can collapse these guardrails and allow jailbreaks.
- Publish-deployment Guardrails: Output moderation, steady analysis, retrieval-augmented validation, fallback routing. Unit 42’s June 2025 benchmark revealed excessive false positives carefully instruments.
Reliable AI: Ideas and Pillars
Reliable AI isn’t a single method however a composite of key rules:
- Robustness: The mannequin ought to behave reliably underneath distributional shift or adversarial enter.
- Transparency: The reasoning path should be explainable to customers and auditors.
- Accountability: There needs to be mechanisms to hint mannequin actions and failures.
- Equity: Outputs shouldn’t perpetuate or amplify societal biases.
- Privateness Preservation: Strategies like federated studying and differential privateness are crucial.
Legislative deal with AI governance has risen: in 2024 alone, U.S. companies issued 59 AI-related rules throughout 75 nations. UNESCO has additionally established international moral tips.
LLM Analysis: Past Accuracy
Evaluating LLMs extends far past conventional accuracy benchmarks. Key dimensions embrace:

- Factuality: Does the mannequin hallucinate?
- Toxicity & Bias: Are the outputs inclusive and non-harmful?
- Alignment: Does the mannequin observe directions safely?
- Steerability: Can it’s guided primarily based on consumer intent?
- Robustness: How effectively does it resist adversarial prompts?
Analysis Strategies
- Automated Metrics: BLEU, ROUGE, perplexity are nonetheless used however inadequate alone.
- Human-in-the-Loop Evaluations: Skilled annotations for security, tone, and coverage compliance.
- Adversarial Testing: Utilizing red-teaming strategies to emphasize check guardrail effectiveness.
- Retrieval-Augmented Analysis: Reality-checking solutions in opposition to exterior information bases.
Multi-dimensional instruments resembling HELM (Holistic Analysis of Language Fashions) and HolisticEval are being adopted.
Architecting Guardrails into LLMs
The combination of AI guardrails should start on the design stage. A structured strategy consists of:
- Intent Detection Layer: Classifies doubtlessly unsafe queries.
- Routing Layer: Redirects to retrieval-augmented era (RAG) techniques or human assessment.
- Publish-processing Filters: Makes use of classifiers to detect dangerous content material earlier than last output.
- Suggestions Loops: Consists of consumer suggestions and steady fine-tuning mechanisms.
Open-source frameworks like Guardrails AI and RAIL present modular APIs to experiment with these parts.
Challenges in LLM Security and Analysis
Regardless of developments, main obstacles stay:
- Analysis Ambiguity: Defining harmfulness or equity varies throughout contexts.
- Adaptability vs. Management: Too many restrictions cut back utility.
- Scaling Human Suggestions: High quality assurance for billions of generations is non-trivial.
- Opaque Mannequin Internals: Transformer-based LLMs stay largely black-box regardless of interpretability efforts.
Current research present over-restricting guardrails usually leads to excessive false positives or unusable outputs (supply).
Conclusion: Towards Accountable AI Deployment
Guardrails are usually not a last repair however an evolving security internet. Reliable AI should be approached as a systems-level problem, integrating architectural robustness, steady analysis, and moral foresight. As LLMs acquire autonomy and affect, proactive LLM analysis methods will function each an moral crucial and a technical necessity.
Organizations constructing or deploying AI should deal with security and trustworthiness not as afterthoughts, however as central design targets. Solely then can AI evolve as a dependable accomplice reasonably than an unpredictable danger.
FAQs on AI Guardrails and Accountable LLM Deployment
1. What precisely are AI guardrails, and why are they necessary?
AI guardrails are complete security measures embedded all through the AI improvement lifecycle—together with pre-deployment audits, coaching safeguards, and post-deployment monitoring—that assist stop dangerous outputs, biases, and unintended behaviors. They’re essential for making certain AI techniques align with human values, authorized requirements, and moral norms, particularly as AI is more and more utilized in delicate sectors like healthcare and finance.
2. How are giant language fashions (LLMs) evaluated past simply accuracy?
LLMs are evaluated on a number of dimensions resembling factuality (how usually they hallucinate), toxicity and bias in outputs, alignment to consumer intent, steerability (capability to be guided safely), and robustness in opposition to adversarial prompts. This analysis combines automated metrics, human evaluations, adversarial testing, and fact-checking in opposition to exterior information bases to make sure safer and extra dependable AI habits.
3. What are the most important challenges in implementing efficient AI guardrails?
Key challenges embrace ambiguity in defining dangerous or biased habits throughout totally different contexts, balancing security controls with mannequin utility, scaling human oversight for enormous interplay volumes, and the inherent opacity of deep studying fashions which limits explainability. Overly restrictive guardrails also can result in excessive false positives, irritating customers and limiting AI usefulness.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.