
If your organization has funds constraints, buying licensed merchandise like Splunk for logging infrastructure is probably not possible. Thankfully, a robust open-source different exists: ELK (Elasticsearch, Logstash, and Kibana). ELK affords strong logging and visualization capabilities.
At a startup the place I labored, value minimization was a precedence, so I applied ELK for logging.
On this article, I will information you thru organising and configuring the free model of the ELK stack on GCP utilizing Terraform and Ansible. Nevertheless, the identical directions may be adopted to deploy it on different cloud platforms like AWS and Azure.
Why Select ELK?
After thorough analysis, I made a decision to implement the ELK stack on GCP utilizing digital machines (VMs) for logging resulting from its ease of use, wealthy dashboards, and simple setup course of. Whereas I might have deployed it on a GKE cluster, I opted for VMs on the time for numerous causes.
Elasticsearch is an open-source search and analytics engine that permits you to acquire and analyze logs from a number of sources, together with IoT gadgets, software servers, internet servers, and cloud companies. The ELK stack consists of the next elements:
-
Elasticsearch – Shops and indexes log knowledge
-
Logstash – Filters and codecs logs earlier than ingestion
-
Kibana – Gives a graphical consumer interface (GUI) for looking out and visualizing logs
-
Filebeat – A light-weight log shipper put in as an agent on machines producing logs
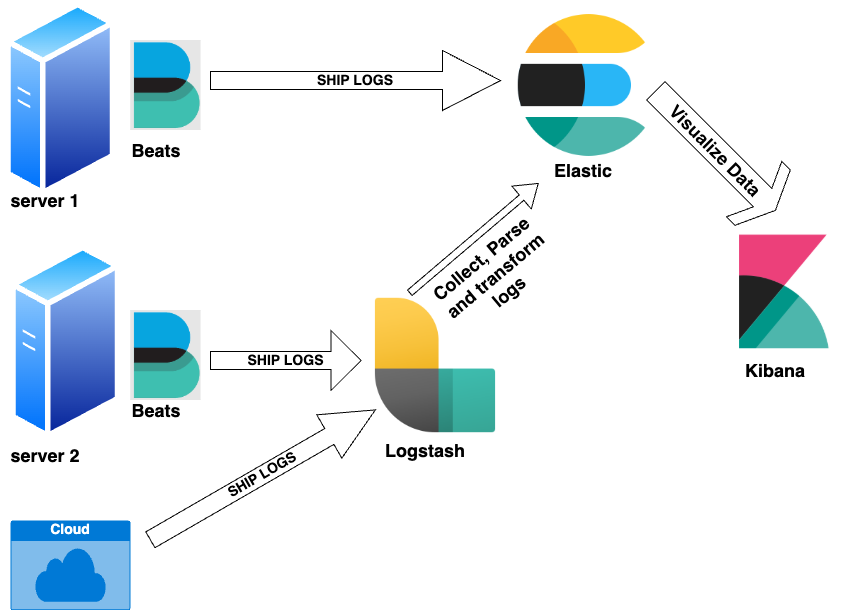
Determine 1
Stipulations
Earlier than organising ELK, guarantee you have got the next:
-
A cloud account (Google Cloud, AWS, or Azure). This information makes use of GCP.
-
Terraform and Ansible put in in your native machine.
-
Correct authentication configured between your native machine and the cloud supplier (Google Cloud or another) with the required entry permissions for Terraform and Ansible.
Half 1: ELK Infrastructure Setup Utilizing Terraform on GCP
The ELK stack consists of assorted nodes, every serving a particular perform to reinforce scalability and failover:
-
Grasp nodes – Handle cluster operations and indexing.
-
Information nodes – Retailer and index log knowledge for search and evaluation.
-
Kibana node – Gives a GUI for log visualization and analytics.
-
Logstash node – Filters, transforms, and ingests logs from numerous sources.
Whereas all functionalities may be mixed on a single node, separating them in a manufacturing atmosphere improves scalability and fault tolerance, relying on the workload.
Create the next recordsdata in a folder the place you intend to run the Terraform code, or clone my Git repository, which accommodates all of the code: GitHub – pradeep-gaddamidi/ELK.
1. create_elk_instances.tf
locals {
config = var.environment_config[terraform.workspace]
cases = [for key, value in local.config.nodes : {
name = key
machine_type = (
can(regex("master_.*", value)) ? local.config.master_machine_type :
can(regex("kibana_.*", value)) ? local.config.kibana_machine_type :
can(regex("logstash_.*", value)) ? local.config.logstash_machine_type :
local.config.node_machine_type
)
zone = (
can(regex(".*_zoneb", value)) ? local.config.region_zones[1] :
can(regex(".*_zonec", worth)) ? native.config.region_zones[2] :
native.config.region_zones[0]
)
network_tags = native.config.network_tags
ssh_keys = native.config.ssh_keys
static_ip_name = key # Modify or go away null as wanted
service_account_name = "elastic" # Modify or go away null as wanted
disk_name = key # Modify or go away null as wanted
disk_type = "pd-standard" # Modify as wanted
disk_size = (
can(regex("master_.*", worth)) ? native.config.master_disk_size :
can(regex("kibana_.*", worth)) ? native.config.kibana_disk_size :
can(regex("logstash_.*", worth)) ? native.config.logstash_disk_size :
native.config.node_disk_size
)
disk_zone = (
can(regex(".*_zoneb", worth)) ? native.config.region_zones[1] :
can(regex(".*_zonec", worth)) ? native.config.region_zones[2] :
native.config.region_zones[0]
)
disk_project = native.config.project_name
}]
}
module "gcp_instance" {
supply = "../../modules/gcp_custom_instance"
gce_image = native.config.gce_image
subnet = native.config.subnet
area = native.config.area # Present solely when creating static IPS
cases = native.cases
use_common_service_account = native.config.use_common_service_account # Present solely when creating a standard service account accross all of the cases
}2. variables.tf
variable "environment_config" {
description = "Configuration per atmosphere"
kind = map(object({
project_name = string
area = string
region_zones = listing(string)
master_machine_type = string
node_machine_type = string
kibana_machine_type = string
logstash_machine_type= string
network_tags = listing(string)
community = string
subnet = string
gce_image = string
ca_bucket_location = string
backup_bucket = string
master_disk_size = quantity
node_disk_size = quantity
kibana_disk_size = quantity
logstash_disk_size = quantity
use_common_service_account = bool
machine_access_scopes= listing(string)
nodes = map(string)
ssh_keys = listing(string)
}))
default = {
nonprod = {
project_name = "nonprod-infra-monitoring"
area = "us-central1"
region_zones = ["us-central1-a", "us-central1-b"]
master_machine_type = "n1-standard-2"
node_machine_type = "n1-standard-2"
kibana_machine_type = "n1-standard-2"
logstash_machine_type= "n1-standard-2"
network_tags = ["elastic", "nonprod"]
community = "tasks/nonprod-networking/international/networks/nonprod-vpc"
subnet = "tasks/nonprod-networking/areas/us-central1/subnetworks/nonprod-sub01"
gce_image = "debian-cloud/debian-12"
ca_bucket_location = "nonprod-elastic-certificates"
backup_bucket = "nonprod-elastic-backup"
master_disk_size = 100
node_disk_size = 510
kibana_disk_size = 100
logstash_disk_size = 100
use_common_service_account = true
machine_access_scopes = ["cloud-platform"]
ssh_keys = []
nodes = {
"nonprod-elastic-master-node1" = "master_zonea"
"nonprod-elastic-data-node1" = "data_zonea"
"nonprod-elastic-data-node2" = "data_zoneb"
"nonprod-elastic-kibana" = "kibana_zonea"
"nonprod-elastic-logstash" = "logstash_zonea"
}
}
prod = {
project_name = "prod-infra-monitoring"
area = "us-central1"
region_zones = ["us-central1-a", "us-central1-b", "us-central1-c"]
master_machine_type = "n2-standard-2"
node_machine_type = "n2-highmem-4"
kibana_machine_type = "n2-standard-2"
logstash_machine_type= "n2-standard-2"
network_tags = ["elastic", "prod"]
community = "tasks/prod-networking/international/networks/prod-vpc"
subnet = "tasks/prod-networking/areas/us-central1/subnetworks/prod-sub01"
gce_image = "debian-cloud/debian-12"
ca_bucket_location = "prod-elastic-certificates"
backup_bucket = "prod-elastic-backup"
master_disk_size = 100
node_disk_size = 3000
kibana_disk_size = 100
logstash_disk_size = 100
use_common_service_account = true
machine_access_scopes = ["cloud-platform"]
ssh_keys = []
nodes = {
"elastic-master-node1" = "master_zonea"
"elastic-master-node2" = "master_zoneb"
"elastic-master-node3" = "master_zonec"
"elastic-data-node1" = "data_zonea"
"elastic-data-node2" = "data_zonea"
"elastic-data-node3" = "data_zoneb"
"elastic-data-node4" = "data_zoneb"
"elastic-data-node5" = "data_zonea"
"elastic-data-node6" = "data_zoneb"
"elastic-kibana" = "kibana_zonea"
"elastic-logstash" = "logstash_zonea"
"elastic-logstash2" = "logstash_zoneb"
"elastic-logstash3" = "logstash_zonec"
}
}
}
}
I’ve created a customized module to provision GCP cases and used it within the create_elk_instances.tf file. Nevertheless, you too can use GCP’s official Terraform module to create VM cases.
module "gcp_instance" {
supply = "./modules/gcp_custom_instance"
The ./modules/gcp_custom_instance folder should have the recordsdata, gcp_custom_vm.tf and variables_custom.tf).
Under is the code for my customized module:
3. gcp_custom_vm.tf
locals {
common_service_account_email = var.use_common_service_account ? google_service_account.common_service_account[0].e-mail : null
}
useful resource "google_compute_instance" "google-compute-instance" {
for_each = { for index, inst in var.cases : inst.title => inst }
title = every.worth.title
machine_type = every.worth.machine_type
zone = every.worth.zone
# allow_stopping_for_update = true
tags = every.worth.network_tags
metadata = {
ssh-keys = be a part of("n", every.worth.ssh_keys)
}
boot_disk {
initialize_params {
picture = var.gce_image
}
}
network_interface {
subnetwork = var.subnet
network_ip = every.worth.static_ip_name != null ? google_compute_address.static_ips[each.value.static_ip_name].tackle : null
}
dynamic "service_account" {
for_each = every.worth.service_account_name != null ? [1] : []
content material {
scopes = var.machine_access_scopes
e-mail = var.use_common_service_account ? google_service_account.common_service_account[0].e-mail : google_service_account.individual_service_account[each.value.name].e-mail
}
}
dynamic "attached_disk" {
for_each = every.worth.disk_name != null ? [1] : []
content material {
supply = google_compute_disk.google-compute-disk[each.value.disk_name].self_link
device_name = "${every.worth.disk_name}-data"
mode = "READ_WRITE"
}
}
}
useful resource "google_compute_disk" "google-compute-disk" {
for_each = { for index, inst in var.cases : inst.disk_name => inst if inst.disk_name != null }
title = "${every.worth.disk_name}-data"
kind = every.worth.disk_type
dimension = every.worth.disk_size
zone = every.worth.disk_zone
undertaking = every.worth.disk_project
}
useful resource "google_service_account" "common_service_account" {
rely = var.use_common_service_account ? 1 : 0
account_id = var.use_common_service_account ? lookup(var.cases[0], "service_account_name", null) : null
display_name = "Service Account"
}
useful resource "google_service_account" "individual_service_account" {
for_each = { for index, inst in var.cases : inst.service_account_name => inst if inst.service_account_name != null && !var.use_common_service_account }
account_id = every.worth.service_account_name
display_name = "Service account for ${every.worth.title}"
}
useful resource "google_compute_address" "static_ips" {
# Solely embrace cases which have static_ip_name outlined
for_each = { for index, inst in var.cases : inst.static_ip_name => inst if inst.static_ip_name != null }
title = every.worth.static_ip_name
address_type = "INTERNAL"
area = var.area
subnetwork = var.subnet
}
output "common_service_account_email" {
worth = native.common_service_account_email
description = "The e-mail of the widespread service account"
}4. variables_custom.tf
variable "cases" {
description = "Listing of occasion configurations"
kind = listing(object({
title = string
machine_type = string
zone = string
network_tags = non-compulsory(listing(string))
ssh_keys = non-compulsory(listing(string))
static_ip_name = non-compulsory(string)
service_account_name = non-compulsory(string)
disk_name = non-compulsory(string)
disk_type = non-compulsory(string)
disk_size = non-compulsory(quantity)
disk_zone = non-compulsory(string)
disk_project = non-compulsory(string)
}))
}
variable "gce_image" {
description = "GCE picture for the cases"
kind = string
default = "debian-cloud/debian-12"
}
variable "subnet" {
description = "Subnet for the community"
kind = string
}
variable "area" {
description = "GCP area"
kind = string
default = "us-central1"
}
variable "use_common_service_account" {
description = "Flag to find out if a standard service account ought to be used for all cases"
kind = bool
default = false
}
variable "machine_access_scopes" {
description = "Scopes for machine entry"
kind = listing(string)
default = ["cloud-platform"]
}
Assign permissions to the service accounts created earlier within the code:
locals {
bucket_config = var.environment_config[terraform.workspace]
}
useful resource "google_storage_bucket_iam_binding" "elastic-backup" {
bucket = native.bucket_config.backup_bucket
function = "roles/storage.objectAdmin"
members = native.config.use_common_service_account ? ["serviceAccount:${module.gcp_instance.common_service_account_email}"] : []
}
useful resource "google_storage_bucket_iam_binding" "elastic-certs" {
bucket = native.bucket_config.ca_bucket_location
function = "roles/storage.objectViewer"
members = native.config.use_common_service_account ? ["serviceAccount:${module.gcp_instance.common_service_account_email}"] : []
}
Create the GCP buckets used for certificates and elastic backups:
useful resource "google_storage_bucket" "elastic-backup" {
title = native.bucket_config.backup_bucket
location = "US"
storage_class = "STANDARD"
uniform_bucket_level_access = true
}
useful resource "google_storage_bucket" "elastic-certs" {
title = native.bucket_config.ca_bucket_location
location = "US"
storage_class = "STANDARD"
uniform_bucket_level_access = true
}
You should use the beneath Terraform instructions to create the above sources:
terraform workspace set nonprod (in the event you use workspaces)
terraform init
terraform plan
terraform applyYou possibly can add new nodes as wanted by updating variables, i.e., including new nodes to the nodes part of the file and re-running the Terraform code. This can provision the brand new knowledge nodes routinely. Now that the ELK infrastructure is ready up, the subsequent step is to put in and configure the ELK software program.
Half 2: Configure the ELK Infrastructure Utilizing Ansible
Stipulations
1. The certificates technology required for safe communication between numerous Elastic nodes may be automated. Nevertheless, I selected to generate them manually by following the ELK guides.
As soon as the certificates are generated, stage them on the GCP bucket elastic-certificates.
2. Ensure your Ansible hosts recordsdata are organized as beneath:
-
All knowledge and grasp nodes are grouped underneath the
elasticpart -
Kibana nodes underneath
kibanapart -
Logstash nodes underneath
logstash -
Information nodes underneath
knowledge -
Grasp nodes underneath
grasp
Create the next recordsdata in a folder the place you intend to run the Ansible playbook. Then, execute the Ansible playbook beneath to put in and configure ELK.
ansible.yaml
---
- title: Set up Elasticsearch pre-reqs on Debian
hosts: all
develop into: sure
duties:
- title: Replace apt repository
apt:
update_cache: sure
- title: Set up default-jre
apt:
title:
- default-jre
state: current
- title: Add Elasticsearch GPG key
apt_key:
url: https://artifacts.elastic.co/GPG-KEY-elasticsearch
state: current
- title: Set up apt-transport-https
apt:
title: apt-transport-https
state: current
- title: Add Elasticsearch repository
apt_repository:
repo: "deb https://artifacts.elastic.co/packages/8.x/apt secure principal"
state: current
filename: elastic-8.x
- title: Replace apt repository
apt:
update_cache: sure
- title: Set up Elasticsearch on Debian
hosts: elastic
develop into: sure
duties:
- title: Set up Elasticsearch
apt:
title: elasticsearch=8.11.2
state: current
- title: Allow Elasticsearch service
ansible.builtin.systemd:
title: elasticsearch.service
enabled: sure
- title: Set up Kibana on Debian
hosts: kibana
develop into: sure
duties:
- title: Set up Kibana
apt:
title: kibana=8.11.2
state: current
- title: Allow kibana service
ansible.builtin.systemd:
title: kibana.service
enabled: sure
- title: Set up logstash on Debian
hosts: logstash
develop into: sure
duties:
- title: Set up logstash
apt:
title: logstash=1:8.11.2-1
state: current
- title: Allow logstash service
ansible.builtin.systemd:
title: logstash.service
enabled: sure
- title: Copy the kibana.yml configuration file to the kibana nodes
hosts: kibana
develop into: sure
duties:
- title: Copy a kibana.yml file
template:
src: "{{ playbook_dir }}/recordsdata/kibana.j2"
dest: /and so forth/kibana/kibana.yml
- title: Copy the pipelines.yml configuration file to the logstash nodes
hosts: logstash
develop into: sure
duties:
- title: Copy a logstash pipelines.yml file
template:
src: "{{ playbook_dir }}/recordsdata/logstash.j2"
dest: /and so forth/logstash/conf.d/pipelines.conf
- title: Copy the elasticsearch_node.yml configuration file to the nodes
hosts: knowledge
gather_facts: sure
develop into: sure
duties:
- title: Get zone information from metadata server
ansible.builtin.uri:
url: http://metadata.google.inner/computeMetadata/v1/occasion/zone
methodology: GET
return_content: sure # Ensures that the content material is returned
headers:
Metadata-Taste: "Google"
register: zone_info
check_mode: no
- title: Extract the zone title
set_fact:
zone_name: "{{ zone_info.content material.cut up("https://dzone.com/")[-1] }}"
- title: Copy a elasticsearch_node.yml file
template:
src: "{{ playbook_dir }}/recordsdata/elasticsearch_node.j2"
dest: /and so forth/elasticsearch/elasticsearch.yml
- title: Copy the elasticsearch_node.yml configuration file to the nodes
hosts: grasp
gather_facts: sure
develop into: sure
duties:
- title: Copy a elasticsearch_master.yml file
template:
src: "{{ playbook_dir }}/recordsdata/elasticsearch_master.j2"
dest: /and so forth/elasticsearch/elasticsearch.yml
- title: Obtain the certificates from the GCS bucket
hosts: elastic
develop into: sure
duties:
- title: certificates
command: gsutil cp gs://nonprod-elastic-certificates/* /and so forth/elasticsearch/certs
- title: Obtain the certificates from the GCS bucket
hosts: kibana
develop into: sure
duties:
- title: certificates
command: gsutil cp gs://nonprod-elastic-certificates/elasticsearch-ca.pem /and so forth/kibana
- title: Obtain the certificates from the GCS bucket
hosts: logstash
develop into: sure
duties:
- title: certificates
command: gsutil cp gs://nonprod-elastic-certificates/elasticsearch-ca.pem /usr/share/logstash/pipeline/elasticsearch-ca.pem
The configuration recordsdata required by the Ansible playbook ought to be positioned within the recordsdata listing. The anticipated recordsdata are listed beneath:
1. elasticsearch_master.j2
node.title: {{ ansible_default_ipv4.tackle }}
node.roles: [ master ]
discovery.seed_hosts:
- 10.x.x.x
- 10.x.x.x
- 10.x.x.x
#cluster.initial_master_nodes:
# - 10.x.x.x
# - 10.x.x.x
# - 10.x.x.x
community.host : {{ ansible_default_ipv4.tackle }}
cluster.title: prod-monitoring
path:
knowledge: /mnt/disks/elasticsearch
logs: /var/log/elasticsearch
cluster.routing.allocation.consciousness.attributes: zone
cluster.routing.allocation.consciousness.drive.zone.values: us-central1-a,us-central1-b
xpack.safety.http.ssl.enabled: true
xpack.safety.http.ssl.keystore.path: /and so forth/elasticsearch/certs/http.p12
xpack.safety.enabled: true
xpack.safety.transport.ssl.enabled: true
xpack.safety.audit.enabled: true
xpack.safety.transport.ssl.verification_mode: certificates
xpack.safety.transport.ssl.keystore.path: /and so forth/elasticsearch/certs/elastic-certificates.p12
xpack.safety.transport.ssl.client_authentication: required
xpack.safety.transport.ssl.truststore.path: /and so forth/elasticsearch/certs/elastic-certificates.p12
xpack.license.self_generated.kind: fundamentalA couple of factors to be famous in regards to the above elastic grasp nodes configuration:
-
We’re utilizing a fundamental (free) license, not a premium one.
-
When Ansible runs on the grasp node, it routinely fills within the IPv4 tackle of the grasp node by default.
-
Uncomment
cluster.initial_master_nodessolely when creating the cluster for the primary time. -
Safety is enabled between:
- Grasp nodes utilizing
xpack.safety.transport.ssl.enabled - Information nodes and Kibana/Logstash utilizing
xpack.safety.http.ssl.enabled
- Grasp nodes utilizing
2. elasticsearch_node.j2
node.title: {{ ansible_default_ipv4.tackle }}
node.roles: [ data, transform, ingest ]
discovery.seed_hosts:
- 10.x.x.x
- 10.x.x.x
- 10.x.x.x
#cluster.initial_master_nodes:
# - 10.x.x.x
# - 10.x.x.x
# - 10.x.x.x
community.host : {{ ansible_default_ipv4.tackle }}
cluster.title: prod-monitoring
path:
knowledge: /mnt/disks/elasticsearch
logs: /var/log/elasticsearch
node.attr.zone: {{ zone_name }}
xpack.safety.http.ssl.enabled: true
xpack.safety.http.ssl.keystore.path: /and so forth/elasticsearch/certs/http.p12
xpack.safety.enabled: true
xpack.safety.transport.ssl.enabled: true
xpack.safety.audit.enabled: true
xpack.safety.transport.ssl.verification_mode: certificates
xpack.safety.transport.ssl.keystore.path: /and so forth/elasticsearch/certs/elastic-certificates.p12
xpack.safety.transport.ssl.client_authentication: required
xpack.safety.transport.ssl.truststore.path: /and so forth/elasticsearch/certs/elastic-certificates.p12
xpack.license.self_generated.kind: fundamental3. kibana.j2
elasticsearch.hosts: ["https://10.x.x.x:9200","https://10.x.x.x:9200","https://10.x.x.x:9200","https://10.x.x.x:9200"]
server.title: kibana
server.host: {{ ansible_default_ipv4.tackle }}
server.port: 443
elasticsearch.username: 'kibana_system'
elasticsearch.password: 'somepassxxxxx'
elasticsearch.ssl.certificateAuthorities: ['/etc/kibana/elasticsearch-ca.pem']
elasticsearch.ssl.verificationMode: 'certificates'
server.ssl.enabled: true
server.ssl.certificates: /and so forth/ssl/kibana/kibana-cert.crt
server.ssl.key: /and so forth/ssl/kibana/kibana-key.key
server.publicBaseUrl: https://elastic.firm.xyz
xpack.encryptedSavedObjects.encryptionKey: zxy123f1318d633817xyz1234
xpack.reporting.encryptionKey: 1xfsyc4ad24176a902f2xyz123
xpack.safety.encryptionKey: cskcjsn60e148a70308d39dxyz123
logging:
appenders:
file:
kind: file
fileName: /var/log/kibana/kibana.log
format:
kind: json
root:
appenders:
- default
- file
pid.file: /run/kibana/kibana.pid4. logstash.j2
enter {
beats {
port => 5044
}
tcp {
port => 50000
}
tcp {
port => 5000
codec => "line"
kind => "syslog"
}
http {
port => 5050
}
google_pubsub {
kind => "pubsub"
project_id => "my-project-123"
matter => "cloud_functions_logs"
subscription => "cloud_functions_logs-sub"
### json_key_file => "/and so forth/logstash/keys/logstash-sa.json"
codec => "json"
}
google_pubsub {
kind => "pubsub"
project_id => "my-project-123"
matter => "cloud_run_logs"
subscription => "cloud_run_logs-sub"
### json_key_file => "/and so forth/logstash/keys/logstash-sa.json"
codec => "json"
}
}
filter {
grok {
match => { "message" => "^%{SYSLOGTIMESTAMP:timestamp} %{SYSLOGHOST:hostname} %{DATA:program}(?:[%{POSINT:pid}])?: %{GREEDYDATA:log_message}" }
}
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
goal => "@timestamp"
}
kv "
value_split => "="
mutate {
remove_field => [ "timestamp" ]
convert => { "pid" => "integer" }
}
}
### Add your filters / logstash plugins configuration right here
output {
elasticsearch {
hosts => ["https://10.x.x.x:9200","https://10.x.x.x:9200","https://10.x.x.x:9200","https://10.x.x.x:9200"]
consumer => "logstash_writer"
password => "mypassxyz"
index => "logs-my-index-%{+yyyy.MM.dd}"
motion => "create"
ssl => true
cacert => '/usr/share/logstash/pipeline/elasticsearch-ca.pem'
}
}A couple of factors to be famous in regards to the above logstash configuration:
-
Within the Logstash configuration above, we use numerous filters akin to
grok,date,kv, andmutateto match and modify incoming logs. Modify in keeping with your wants. -
In each
kibana.j2andlogstash.j2, for “elasticsearch.hosts”, you may specify all knowledge nodes as a listing, permitting requests to be round-robin distributed throughout them. Alternatively, configure an inner load balancer with knowledge nodes because the backend and supply simply the load balancer’s IP. -
Be sure that the
indexandlogstash_writercustomers are created by way of the Kibana console. Moreover, configure the required indices to ingest knowledge from different sources like Filebeat and assign correct permissions to the respective customers. -
Information may be ingested into Elasticsearch by way of Logstash, permitting for vital filtering, or it may be despatched on to knowledge nodes utilizing brokers like Filebeat.
-
In case you are storing any of the above
.j2Jinja recordsdata in a Git repository, and so they comprise delicate info, encrypt them utilizingansible-vault. Discuss with the Ansible documentation to be taught extra about utilizingansible-vault.
Right here is the Filebeat configuration if you wish to ship logs straight from Docker functions. You too can use it to ship logs from another functions.
filebeat.conf
logging.json: true
logging.stage: information
logging.metrics.enabled: false
setup.kibana.host: ${KIBANA_HOST}
setup.ilm.enabled: true
output.elasticsearch:
hosts: ${ELASTIC_HOST}
indices:
- index: "audit-%{+yyyy.MM.dd}"
when.has_fields: ["_audit"]
- index: "logs-%{+yyyy.MM.dd}"
when.has_fields: ["app", "env"]
- index: "invalid-stream-%{+yyyy.MM.dd}"
when.has_fields: ["error.data", "error.message"]
filebeat.autodiscover:
suppliers:
- kind: docker
templates:
- config:
- kind: container
paths:
- /var/lib/docker/containers/${knowledge.docker.container.id}/*.log
processors:
- decode_json_fields:
fields: ["message"]
process_array: false
max_depth: 1
goal: ""
overwrite_keys: false
add_error_key: true
As soon as ELK is ready up, you may configure knowledge backups referred to as snapshots to the ‘elastic-backup’ GCS bucket by way of the Kibana console.
Conclusion
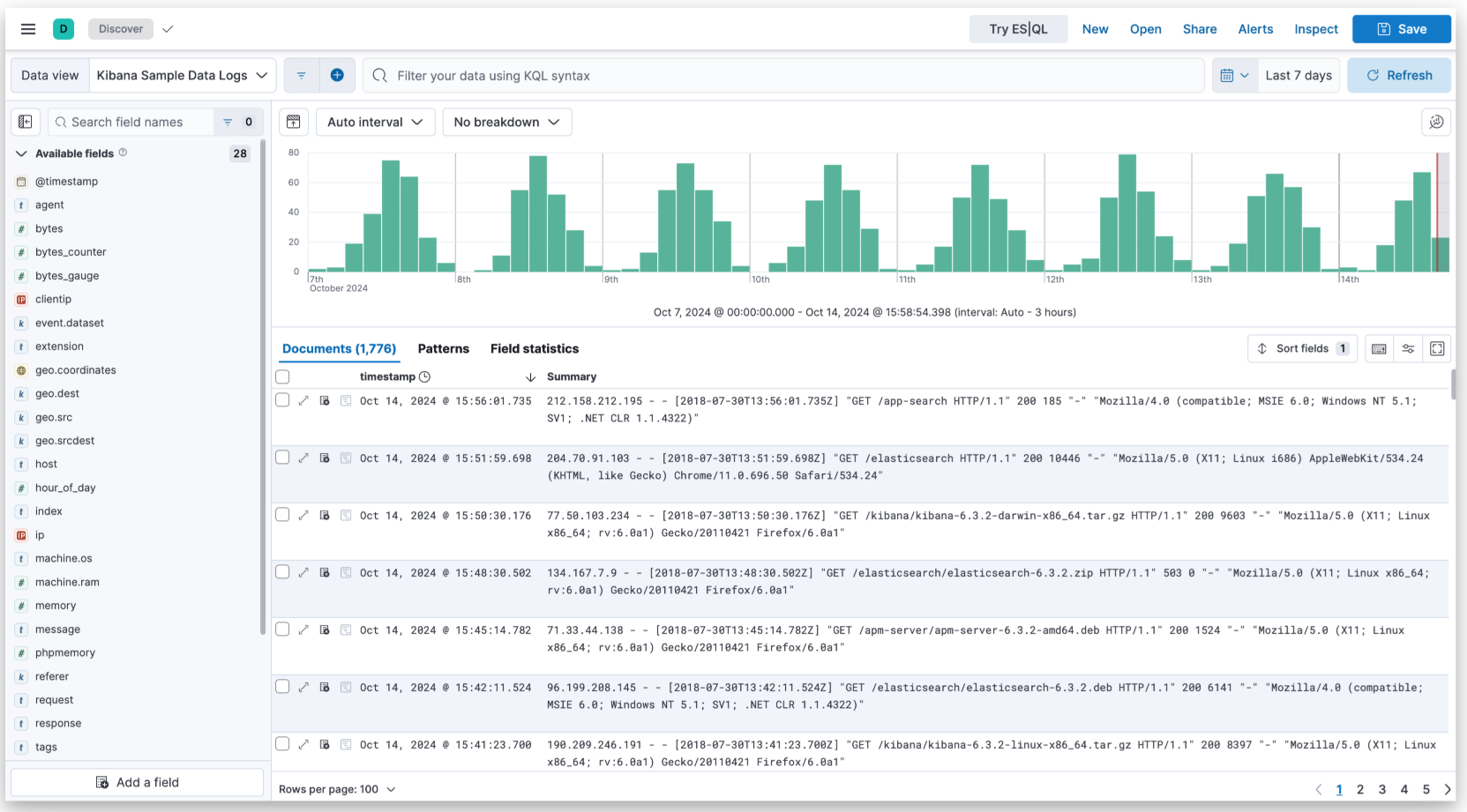
With knowledge being ingested from numerous sources, akin to Filebeat, into the Elasticsearch cluster, you may entry Kibana’s UI to look logs (Determine 2), create visualizations, monitor logs, and arrange alerts successfully.





