NVIDIA has simply launched Canary-Qwen-2.5B, a groundbreaking computerized speech recognition (ASR) and language mannequin (LLM) hybrid, which now tops the Hugging Face OpenASR leaderboard with a record-setting Phrase Error Charge (WER) of 5.63%. Licensed beneath CC-BY, this mannequin is each commercially permissive and open-source, pushing ahead enterprise-ready speech AI with out utilization restrictions. This launch marks a major technical milestone by unifying transcription and language understanding right into a single mannequin structure, enabling downstream duties like summarization and query answering immediately from audio.
Key Highlights
- 5.63% WER – lowest on Hugging Face OpenASR leaderboard
- RTFx of 418 – excessive inference pace on 2.5B parameters
- Helps each ASR and LLM modes – enabling transcribe-then-analyze workflows
- Industrial license (CC-BY) – prepared for enterprise deployment
- Open-source through NeMo – customizable and extensible for analysis and manufacturing

Mannequin Structure: Bridging ASR and LLM
The core innovation behind Canary-Qwen-2.5B lies in its hybrid structure. In contrast to conventional ASR pipelines that deal with transcription and post-processing (summarization, Q&A) as separate phases, this mannequin unifies each capabilities by means of:

- FastConformer encoder: A high-speed speech encoder specialised for low-latency and high-accuracy transcription.
- Qwen3-1.7B LLM decoder: An unmodified pretrained massive language mannequin (LLM) that receives audio-transcribed tokens through adapters.
Using adapters ensures modularity, permitting the Canary encoder to be indifferent and Qwen3-1.7B to function as a standalone LLM for text-based duties. This architectural resolution promotes multi-modal flexibility — a single deployment can deal with each spoken and written inputs for downstream language duties.
Efficiency Benchmarks
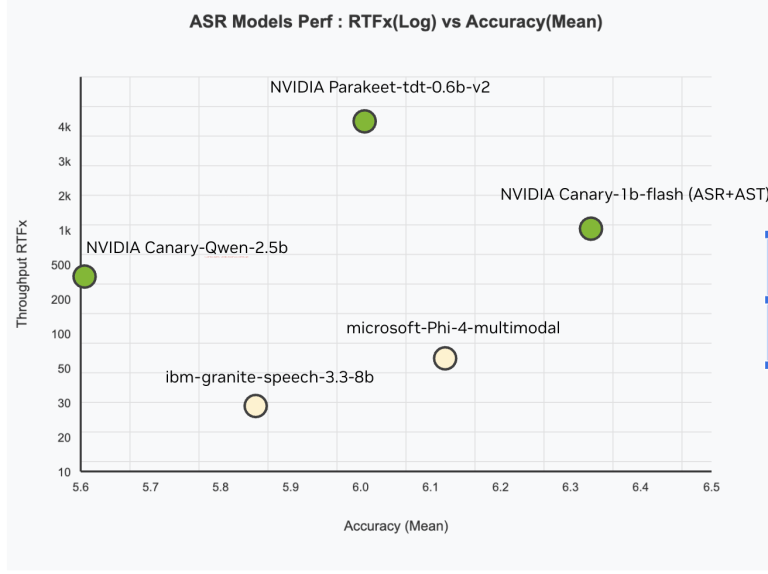
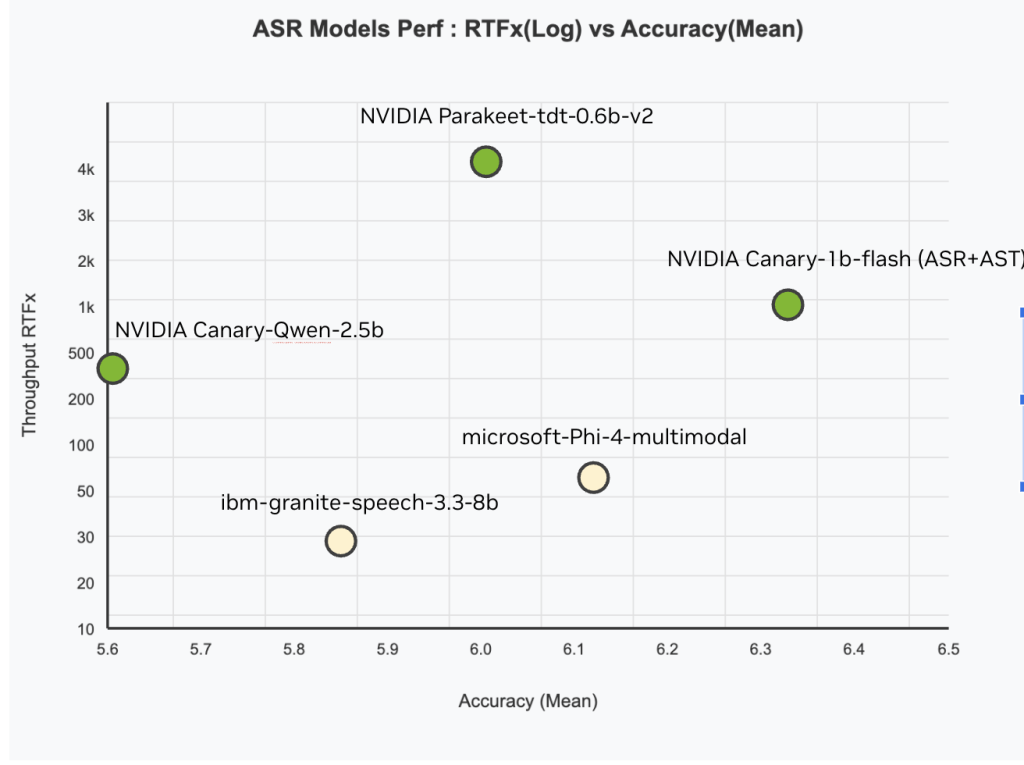
Canary-Qwen-2.5B achieves a document WER of 5.63%, outperforming all prior entries on Hugging Face’s OpenASR leaderboard. That is notably notable given its comparatively modest measurement of 2.5 billion parameters, in comparison with some bigger fashions with inferior efficiency.
| Metric | Worth |
|---|---|
| WER | 5.63% |
| Parameter Depend | 2.5B |
| RTFx | 418 |
| Coaching Hours | 234,000 |
| License | CC-BY |
The 418 RTFx (Actual-Time Issue) signifies that the mannequin can course of enter audio 418× sooner than real-time, a crucial characteristic for real-world deployments the place latency is a bottleneck (e.g., transcription at scale or dwell captioning techniques).

Dataset and Coaching Regime
The mannequin was educated on an in depth dataset comprising 234,000 hours of numerous English-language speech, far exceeding the size of prior NeMo fashions. This dataset consists of a variety of accents, domains, and talking kinds, enabling superior generalization throughout noisy, conversational, and domain-specific audio.
Coaching was carried out utilizing NVIDIA’s NeMo framework, with open-source recipes accessible for neighborhood adaptation. The combination of adapters permits for versatile experimentation — researchers can substitute completely different encoders or LLM decoders with out retraining total stacks.
Deployment and {Hardware} Compatibility
Canary-Qwen-2.5B is optimized for a variety of NVIDIA GPUs:
- Information Heart: A100, H100, and newer Hopper/Blackwell-class GPUs
- Workstation: RTX PRO 6000 (Blackwell), RTX A6000
- Client: GeForce RTX 5090 and under
The mannequin is designed to scale throughout {hardware} lessons, making it appropriate for each cloud inference and on-prem edge workloads.
Use Circumstances and Enterprise Readiness
In contrast to many analysis fashions constrained by non-commercial licenses, Canary-Qwen-2.5B is launched beneath a CC-BY license, enabling:
- Enterprise transcription companies
- Audio-based data extraction
- Actual-time assembly summarization
- Voice-commanded AI brokers
- Regulatory-compliant documentation (healthcare, authorized, finance)
The mannequin’s LLM-aware decoding additionally introduces enhancements in punctuation, capitalization, and contextual accuracy, which are sometimes weak spots in ASR outputs. That is particularly worthwhile for sectors like healthcare or authorized the place misinterpretation can have pricey implications.
Open: A Recipe for Speech-Language Fusion
By open-sourcing the mannequin and its coaching recipe, the NVIDIA analysis group goals to catalyze community-driven advances in speech AI. Builders can combine and match different NeMo-compatible encoders and LLMs, creating task-specific hybrids for brand spanking new domains or languages.
The discharge additionally units a precedent for LLM-centric ASR, the place LLMs aren’t post-processors however built-in brokers within the speech-to-text pipeline. This strategy displays a broader development towards agentic fashions — techniques able to full comprehension and decision-making primarily based on real-world multimodal inputs.
Conclusion
NVIDIA’s Canary-Qwen-2.5B is greater than an ASR mannequin — it’s a blueprint for integrating speech understanding with general-purpose language fashions. With SoTA efficiency, industrial usability, and open innovation pathways, this launch is poised to turn out to be a foundational instrument for enterprises, builders, and researchers aiming to unlock the subsequent technology of voice-first AI purposes.
Try the Leaderboard, Mannequin on Hugging Face and Attempt it right here. All credit score for this analysis goes to the researchers of this venture.
| Attain essentially the most influential AI builders worldwide. 1M+ month-to-month readers, 500K+ neighborhood builders, infinite potentialities. [Explore Sponsorship] |
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.